生成效果演示:
图片:

音频:
暂时无法在飞书文档外展示此内容
下面是生成的视频效果:
暂时无法在飞书文档外展示此内容
因为ai驱动会改变口形眼神,有时候跟原图看起来不太像,但是总体来说SadTalker是开源数字人项目里效果比较好的了,特别是他的口形,中文还是比较像的,感觉比D-ID要像一些。其他方面,比如自然程度,画质比起D-ID要差一些,当然更别说国内几家大厂的收费数字人项目了,他们身体,手势都有,挺像真人的,所以需要自己判断下使用场景。
SadTalker的安装及使用方法:
SadTalker主页:https://github.com/Winfredy/SadTalker
安装步骤:
1、安装NVIDIA cuda11.3
安装方法看这篇文章:https://blog.csdn.net/zzjcymbq/article/details/125040993
注意不要这篇文章最后一步 pytorch配置,后面在“项目下载和运行环境配置”会安装pytorch
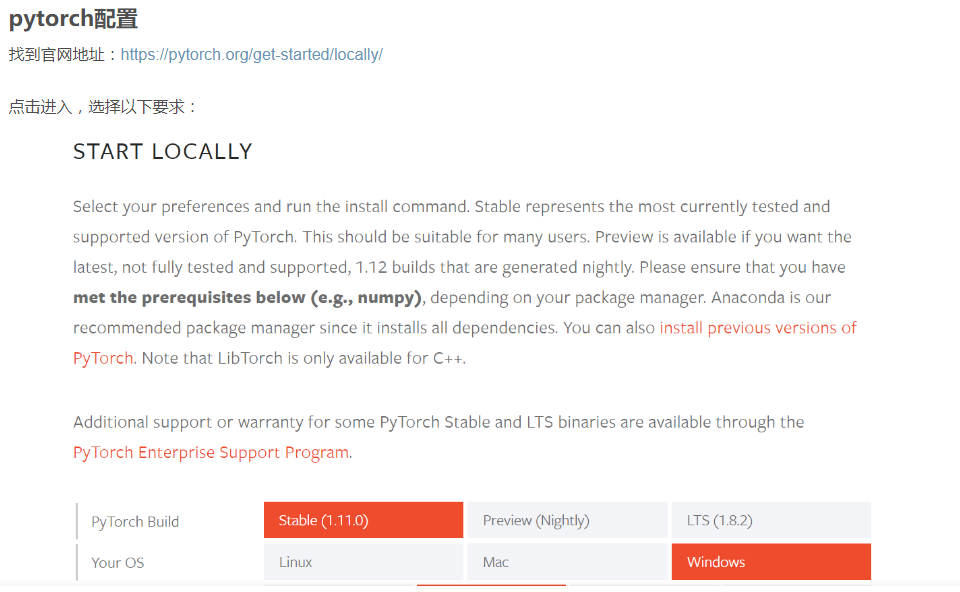
2、安装 anaconda
由于这个项目是python开发的所以需要先安装一个方便管理python的工具anaconda
安装方法可以看这边教程:https://blog.csdn.net/qq_45344586/article/details/124028689
3、项目下载和运行环境配置
(1)下载文件并解压
因为github以及相关模型直接下载会比较慢,我打包上传到百度网盘了
项目源码百度盘:https://pan.baidu.com/s/1_2qdL8OAFO-RBrtBpicAqQ?pwd=sm6w
从网盘下载后解压到电脑某个盘,这里举例就下载解压到D盘了
(2)命令行安装
点击开始菜单找到前面已经安装好的 Anaconda Prompt
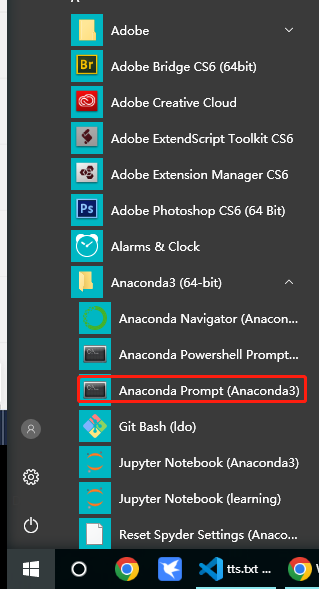
挨着输入下面的命令,注意“#”后面的文字是注释,不要在命令行里输入
每一行命令输完后按回车,有的步骤安装过程比较久需要耐心等待,有几步安装过程中会询问是否安装,需要输入 “y”确认
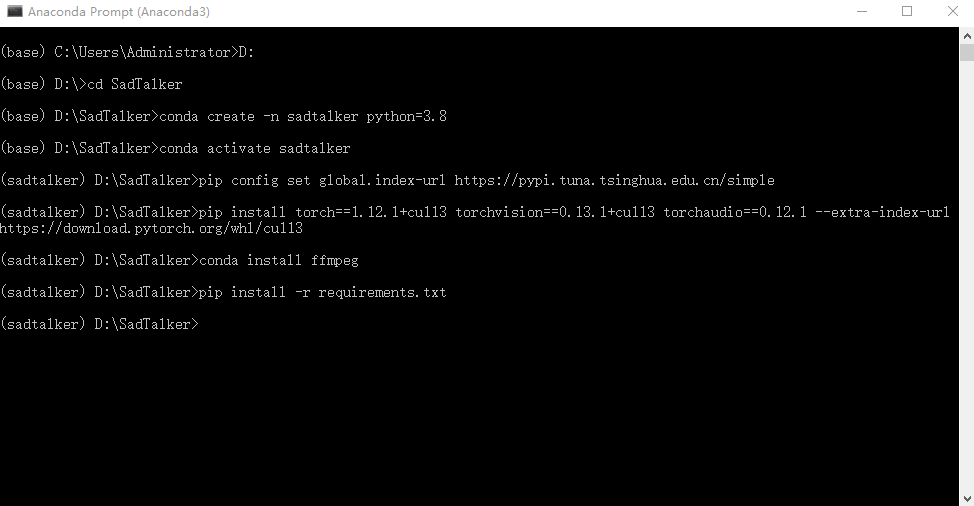
#进入D盘 D: #进入SadTalker项目目录 cd SadTalker #创建一个python3.8 名为sadtalker的虚拟环境 conda create -n sadtalker python=3.8 #激活名为sadtalker的虚拟环境 conda activate sadtalker #pip切换到清华源提高下载速度 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple #安装pytorch及相关包 pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 –extra-index-url https://download.pytorch.org/whl/cu113 #安装视频处理工具ffmpeg conda install ffmpeg #安装项目相关依赖 pip install -r requirements.txt
(3) 复制gfpgan权重文件到虚拟环境
在刚才的命令行工具里输入命令查看虚拟环境路径
conda info
把SadTalker源代码里面的:gfpgan\weights\GFPGANv1.4.pth 剪切到虚拟环境的 Lib\site-packages\gfpgan\weights 目录下
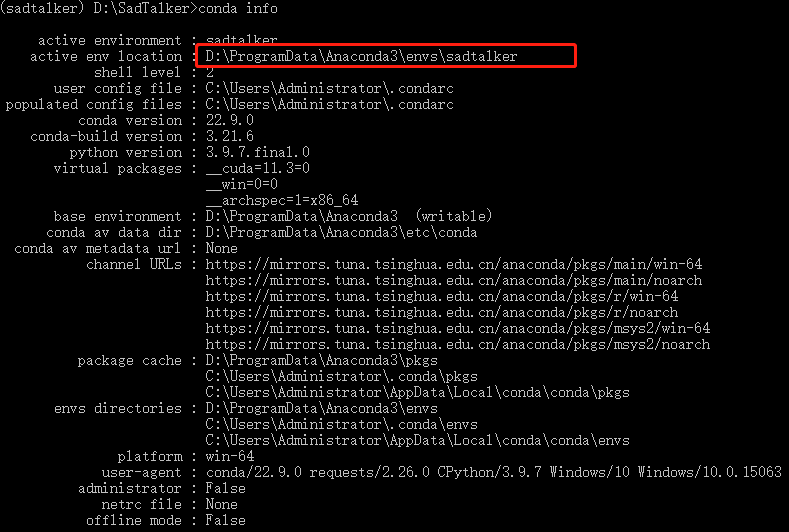
举例:
我的虚拟环境就是截图红框路径,所以需要把gfpgan\weights\GFPGANv1.4.pth 剪切到虚拟环境的 D:\ProgramData\Anaconda3\envs\sadtalker\Lib\site-packages\gfpgan\weights 目录下
使用方法:
提前准备好语音文件和一张图片,这里假设你已经准备好语音和图片了(需要做某个人物声音的,可以用相关的声音克隆项目克隆声音,空了我再写一篇声音克隆的教程)
把语音文件放到SadTalker\examples\driven_audio目录下
把图片放到SadTalker\examples\source_image目录下
1、基础使用命令
然后输入下面的命令
#基础使用 #python inference.py –driven_audio <audio.wav> –source_image <picture.png> –enhancer gfpgan #–driven_audio后面需要写音频文件路径,–source_image后面写图片的路径,下面是一个例子 python inference.py –driven_audio D:\SadTalker\examples\driven_audio\bus_chinese.wav –source_image D:\SadTalker\examples\source_image\full_body_2.png –enhancer gfpgan
等待执行完成后,就可以在SadTalker\results下面的文件夹里面找到生成的结果了
效果如下:
暂时无法在飞书文档外展示此内容
2、更多命令参数
首先看下相关参数:
| 参数 | 配置 | 默认 | 说明 |
| 增强模式 | –enhancer | 无 | 通过人脸恢复网络使用gfpgan或RestoreFormer增强生成的人脸 |
| 背景增强剂 | –background_enhancer | 无 | 用于realesrgan增强完整视频。 |
| 静态模式 | –still | 不设置 | 使用与原始图像相同的姿势参数,减少头部运动。 |
| 表达模式 | –expression_scale | 1 | 较大的值将使表情运动更强。 |
| 保存路径 | –result_dir | ./results | 该文件将保存在较新的位置。 |
| 预处理 | –preprocess | crop | 在裁剪后的输入图像中运行并生成结果。其他选择:resize,其中图像将调整为特定分辨率。full运行完整的图像动画,使用 with–still以获得更好的效果。 |
细心地同学可能会发现一个问题,上面的基础使用,用到的图片是一张半身照,但是生成的视频是只有头部了
对,这个是需要参数控制的,接下来我们加上–preprocess full 和 –still这两个参数
python inference.py –driven_audio D:\SadTalker\examples\driven_audio\bus_chinese.wav –source_image D:\SadTalker\examples\source_image\full_body_2.png –enhancer gfpgan –preprocess full –still
–preprocess full 表示完整图片
–still 可以减少头部运动
第一个参数好理解,为什么会有第二个参数呢? 原因是,项目在用完整图片生成视频的时候,头部在动,但是肩膀会保持不动,交接处就会产生比较扭曲的现象,加上–still后就可以防止交接处扭曲,但是整个视频就几乎只有眼睛和口型的变化了,看起来没那么自然。其他参数,也可以自己试一试。
暂时无法在飞书文档外展示此内容
暂时无法在飞书文档外展示此内容
总结:
整体来说,对质量要求不那么高的场景,SadTalker还是能用一用,毕竟是免费的。然后参数的话想要自然就用基础命令,想要完整图片生成就加上那两个参数。
最后这个环境如果是小白,搭建其实还是比较麻烦的,我想的是租一台云服务器,然后搭建好webui版的,大家可以直接上传语音和图片直接生成,甚至可以把语音克隆功能也搭建好。
有需要的小伙伴可以留言,要是人多我们可以搭建个试试。
再来几个演示:
暂时无法在飞书文档外展示此内容
暂时无法在飞书文档外展示此内容
暂时无法在飞书文档外展示此内容
暂时无法在飞书文档外展示此内容
暂时无法在飞书文档外展示此内容
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...

最专业、最全面的人工智能学习平台,提供最新的AI技术、AI设计、AI导航、AI做图、虚拟人等内容,让您全面了解人工智能技术领域的最新动态,AI学习入门必修都在这里!
{kind=link}
{kind=link}
