摘要: Explore remarkable AI concepts such as Word2Vec and ResNets. Word2Vec revolutionizes language understanding, while ResNets conquer depth challenges. Discover the future of AI.
AI Learning and Breakthroughs
Let’s delve into some remarkable ideas that left the AI community in awe, just like GAN. Machine learning, as a cutting-edge field, is not short of fascinating concepts. Let’s start with something seemingly “simple.”
Word Embedding: Transforming Language into Vectors
As the name suggests, Word2Vec is all about converting language into mathematical vectors. While it may sound straightforward, when Mikolov and his team introduced this concept in 2013, it sent shockwaves through the community. Back then, people still considered words as discrete entities. However, Word2Vec managed to capture subtle relationships within language. For instance, through simple vector operations, we can get “king” – “man” + “woman” ≈ “queen.” The model learned these “implicit meanings”!
The primary goal of Word2Vec is to map words from natural language into a high-dimensional space, where semantically related words are close to each other. In other words, a word’s meaning is defined by the words surrounding it.
Applying Word2Vec involves two phases: model creation and obtaining word vectors. During model creation, a neural network is built using training data. However, after training, the focus shifts to the model’s output – the neural network’s weight matrix (word vectors).
There are two main training methods: Continuous Bag of Words (CBOW) and Skip-Gram. CBOW aims to estimate the center word using context words, similar to a fill-in-the-blank test. In contrast, Skip-Gram predicts the surrounding context words from the center word.
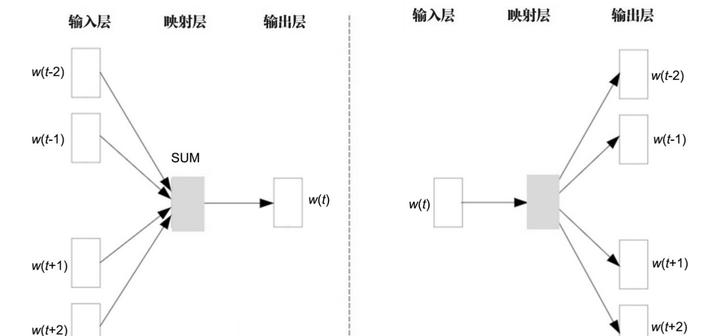
Both CBOW and Skip-Gram models are essentially shallow neural networks. Their objective is to predict the probability of each word being a neighboring word of a given word from the vocabulary, based on the context words.
Other than the input layer for data, CBOW and Skip-Gram models have two primary network layers: the mapping layer (also called the hidden layer) and the output layer. Since these models are trained on unlabeled data, they are considered self-supervised learning models.
Each word in the input layer is represented through one-hot encoding, where each word is transformed into an N-dimensional vector, with V denoting the total number of words in the vocabulary. In this encoding, one dimension corresponds to the word’s position in the dictionary and is marked as 1, while all other dimensions are set to 0.
The mapping layer consists of K hidden neurons, which form an N×K weight matrix with N representing the input’s dimension. Similarly, the output layer is N-dimensional (representing the vocabulary) and is connected to the K-dimensional vector of the mapping layer, forming a K×N weight matrix, where K denotes the embedding dimension for each word. Each dimension corresponds to a specific word in the vocabulary. Finally, the output layer is standardized using the Softmax function to yield the likelihood of each word’s generation.
During training, Word2Vec employs a simple but effective technique called negative sampling, which updates only one positive example and a few negative examples, accelerating the training process.
If you’re interested in Word2Vec and similar techniques, you might want to explore Sun Zhigang’s introductory AI course (if you’re lucky, you might catch a free session). Sun completed ChatALL.ai in just a month, showcasing a deep understanding of large models and machine learning strategies.
Residual Networks (ResNets): Overcoming Depth Challenges
After Word2Vec’s success with shallow neural networks, researchers started to explore deeper models. However, deep models often faced issues like “vanishing gradients” or “exploding gradients,” especially when training very deep neural networks.
Imagine playing the telephone game, where everyone needs to pass a message to the next person – in this analogy, the message represents gradients, and each person represents a layer of a neural network. During the transfer, minor alterations can accumulate, leading to a message that is vastly different from the original. In deep networks, early gradients might diminish at each layer, causing later layers to lack guidance – this is called “vanishing gradients.” Conversely, “exploding gradients” refers to gradients growing uncontrollably, causing learning to go haywire.
In 2015, ResNet (Residual Network) emerged, introducing a solution to these problems through residual connections.
Traditional deep learning models typically attempt to learn the complete representation of the data at each layer. ResNets proposed a surprising idea: why not let each layer learn the “residual” or “change” in comparison to the previous layer?

相关文章

{kind=link}
{kind=link}
