一、Nougat模型的应用功能
Meta AI推出了一个用于科研的OCR工具 Nougat,它的使用功能是:
1.将论文的PDF文档转换为MultiMarkdown的文本Text,并且经过千寻本人的实际测试,即使是扫描版的PDF文档(因扫描文本有畸变)也能转换。
2. 通过OCR的文本提取扫描技术,提取出来论文PDF的文字公式,将复杂一些的论文中的数学公式、表格、文字都能提取出来,进行复用。

二、Nougat模型的应用效果
说是这么说,那么实际的效果到底怎么样呢?我们先睹为快,对于科研论文中的数学公式,不止简单的公式还有复杂的公式,对于带有上、下标的数学格式也精准识别,能准确地转换。
如图使用Nougat模型转换复杂的数学公式
对于一些因扫描导致文档凹凸不平、文本畸形的PDF文档,Nougat模型也能轻松转换。
1.PDF文档的公式扫描:

PDF文档的表格扫描:
不过美中不足的是PDF文档中的图片,如柱状图、折线图这些,Nougat 目前还不能呈现。Nougat 还不能转换PDF文档中的图片。但是Nougat模型 对于搞科研码论文的老师同学们,那些经常流连于各种PDF文献中的人,这是一款很实用的OCR文本处理工具了。
三、Nougat模型的工作原理

Meta的 Nougat 是一个编码器 – 解码器 Transformer 架构,允许端到端的训练,并以 Donut 架构为基础。该模型不需要任何 OCR 相关输入或模块,文本由网络隐式识别。该方法的概述见下图 1。
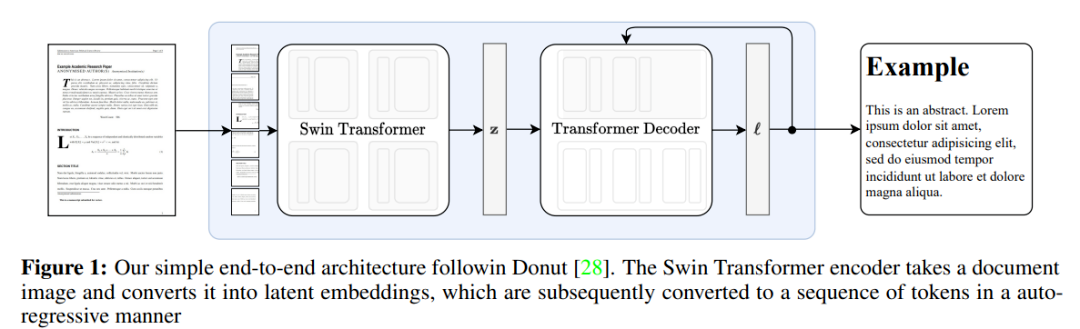
Nougat 建立在Donut架构之上,是一个编码器 – 解码器 Transformer 架构
具体模型的构造:
Nougat 用到了 2 个 Swin Transformer ,一个参数量为 350M,可处理的序列长度为 4096,另一参数量为 250M,序列长度为 3584。
Nougat 使用具有交叉注意力的Transformer解码器架构将编码图像z解码为token序列,使用贪婪解码生成文本。
Nougat 使用数据增强:使用一些变换(如包括侵蚀、扩张、高斯噪声、高斯模糊、位图转换、图像压缩、网格变形和弹性变换等)来模拟扫描文件的不完美和多变性。
四、Nougat模型的训练数据集
Nougat 的数据增强,使用一些变换来模拟扫描文件的不完美和多变性,每种变换的效果概览。对于一个专注处理科学文档的 Nougat,训练模型所需的数据集的构建显得十分重要。
Meta AI 团队使用了来自arxiv、PubMed Central等平台的科学论文PDF数据集,以及来自作者的相应LaTeX源代码。这一数据集总共超过800万页组成。
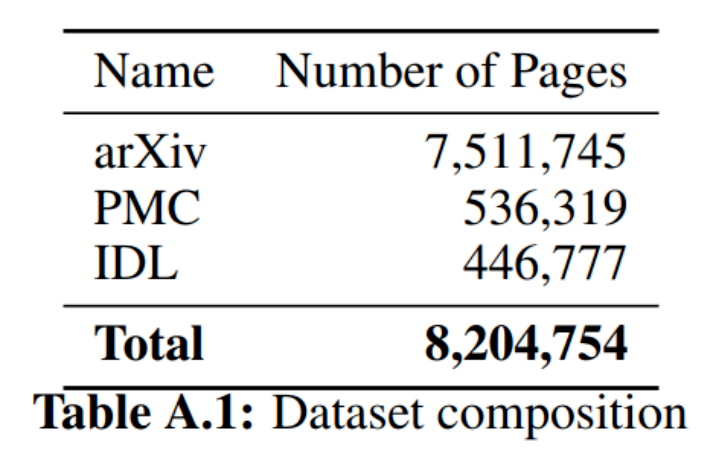
Nougat 的数据集构成
在处理数据集的过程中,Meta研究团队将不同来源的数据进行了合适的处理,下图展示了他们对 arXiv 文章进行源代码收集并编译 PDF 的过程:先将原文档转换为HTML,然后再转换为Markdown格式。
研究团队根据 PDF 文件中的分页符拆分Markdown文件,并将每个页面栅格化为图像以创建最终的配对数据集。在编译过程中,LaTeX 编译器自动确定 PDF 文件的分页符。

源文件被转换成 HTML,然后再转换成 Markdown
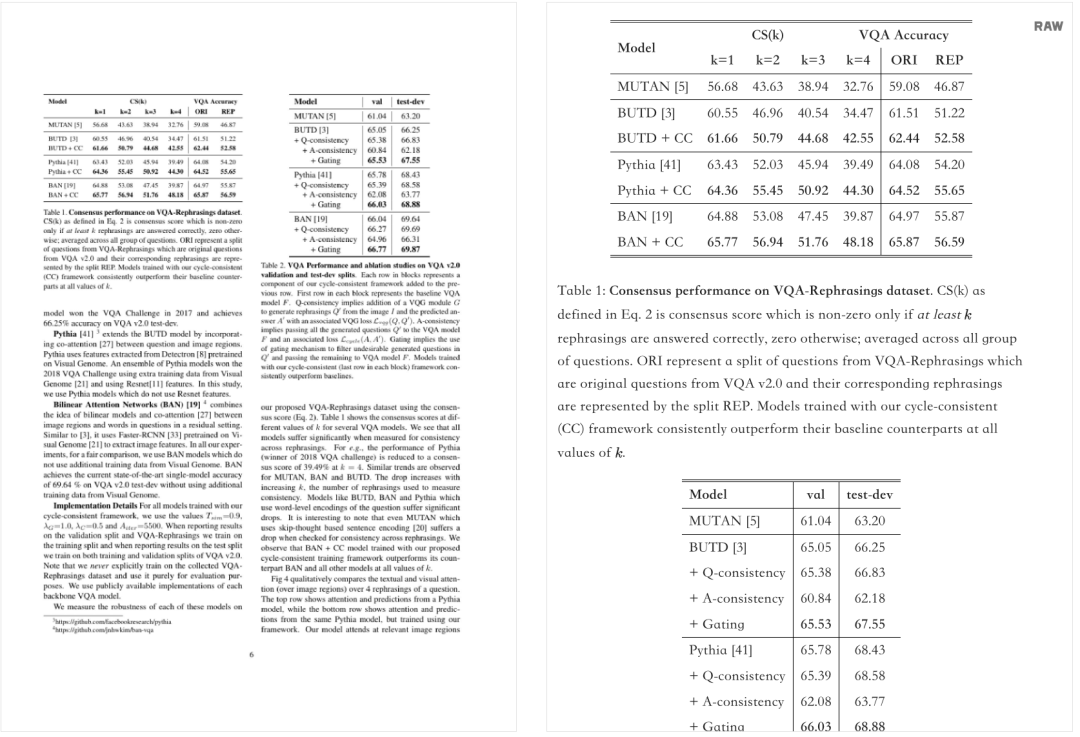
在论文的实验部分,让 Nougat 从论文中提取纯文本、数学公式以及表格,测试的准确率等指标结果如下表1所示。
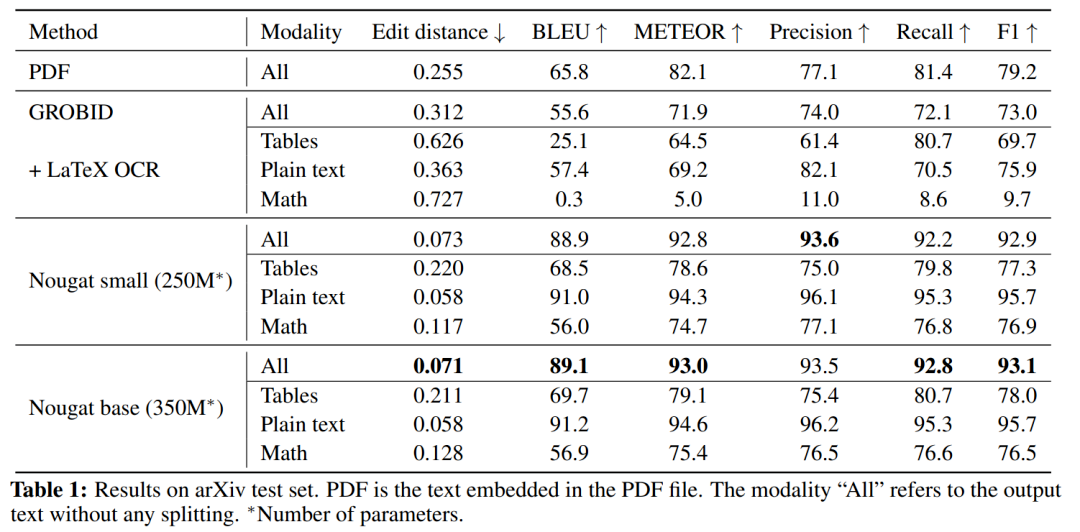
表 1 Nougat 与其他文档转换方法的实验结果
从上表1可以看到,Nougat 明显优于其他方法,在所有指标中取得最高分,并且具有 250M 参数模型的性能与 350M 参数模型相当。
对于纯文本,Nougat 在BLEU分数超过91%,准确率超过96%。
相比纯文本,数学公式和表格的性能较低,准确率均略高于75%。但比经典方法GROBID可靠,后者的数学公式准确率略只有11%。
五、Nougat模型使用教程
安装环境推荐

2.GPU硬件环境推荐使用
在实际使用上,Meta 表示 Nougat 生成速度在很大程度上取决于给定页面上的文本量。以配备 NVIDIA A10G 显卡和 24GB VRAM 机器的环境为例,Nougat 可并行处理 6 个页面。
在不进行任何推理优化的情况下,350M参数量的 Nougat 每批次平均生成时间为 19.5s(token 数≈1400),与经典方法(GROBID 10.6 PDF/s)相比速度还是非常慢的,但 Nougat 能够正确解析数学公式。
安装Nougat插件
pip install git+https://github.com/facebookresearch/nougat
对PDF文件进行扫描
$ nougat path/to/file.pdf -o output_directory
因为模型推理的时间比较长,因此默认的推理模型为:0.1.0-small
优化后的模型:0.1.0-base,使用以下的命令:
$ nougat path/to/file.pdf -o output_directory -m 0.1.0-base
这项研究不仅在从数字生成的 PDF 中提取文本方面,而且在转换扫描论文和教科书方面都显示出了巨大的潜力。我觉得这是一个很有意思的实践。
和传统的PDF文档转换方法不同,它不依赖于 OCR 或嵌入式文本表示,而是完全依赖于光栅化的文档页面。
六、Hugging Face社区的部署应用
进入Hugging Face社区的Nougat模型接口调用应用,进入链接,点击即可
使用方法也是很简单的,点击左侧的“上传PDF”,或者去Arxiv论文托管网站上获取论文的链接:
点击“RUN NOUGAT”的按钮进行推理
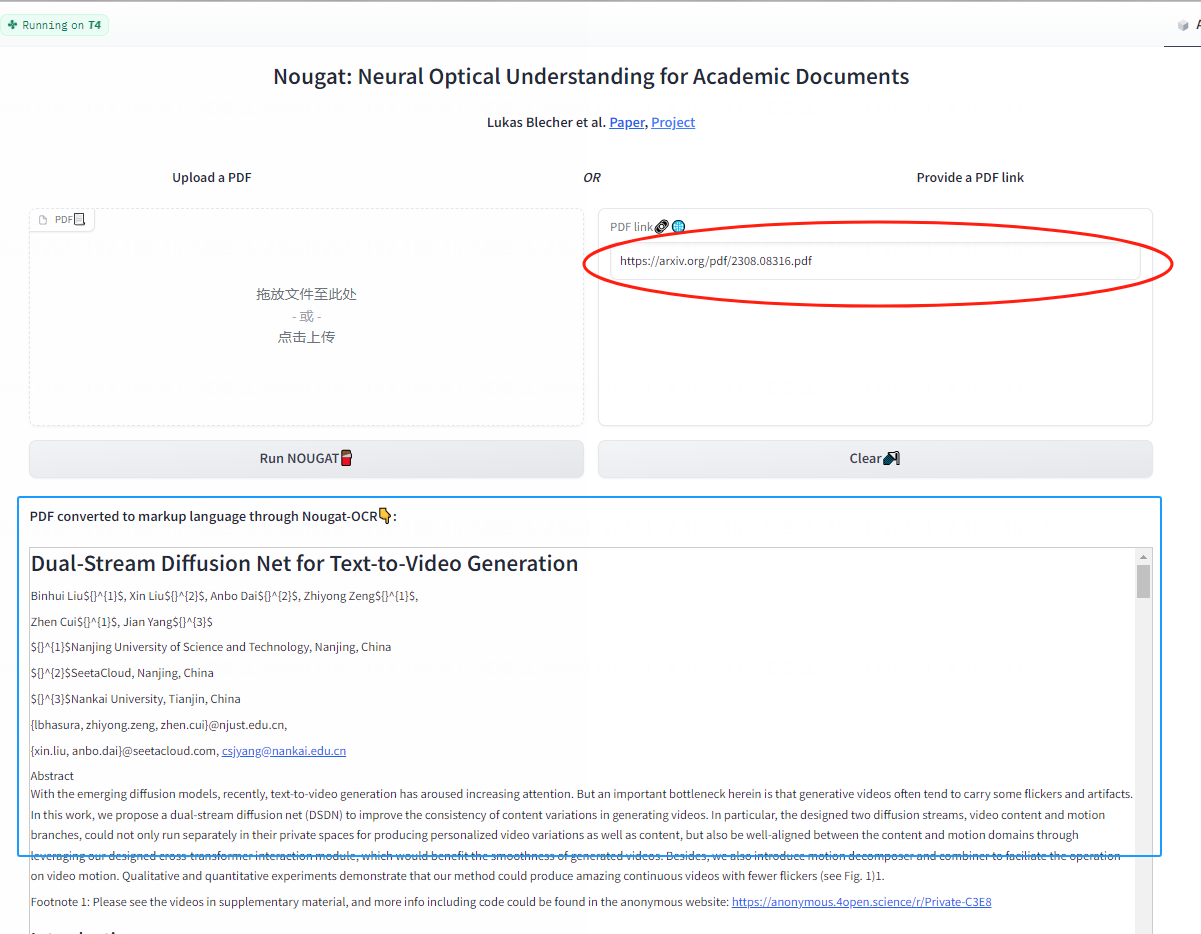
以下为实际的结果,真的不错。在结果栏里面识别文本即可在使用。怎么样还是不错的吧!赶快试试吧!
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...

最专业、最全面的人工智能学习平台,提供最新的AI技术、AI设计、AI导航、AI做图、虚拟人等内容,让您全面了解人工智能技术领域的最新动态,AI学习入门必修都在这里!
{kind=link}
{kind=link}
