阿里云开源通义千问70亿参数大模型,对国内大模型行业将产生哪些影响?
一、阿里云开源大模型——QWen-7B和QWen-7b-Chat
阿里云今天宣布开源了两款大模型——QWen-7B和QWen-7b-Chat。这两个模型的参数规模都达到了70亿。目前,这两个模型已经在Hugging Face和ModelScope平台上开放,并且是免费可商用的。阿里云在4月份推出了通义千问聊天机器人,算是比较早的一批,不过早期是通过内测制度对少数用户开放的。而现在,经过了4个月的发展,国内大模型行业已经发展成了“百模大战”的局势。正是在这个背景下,阿里云选择在开源领域继续向前迈进。对于用户来说,这无疑是一个喜闻乐见的消息。
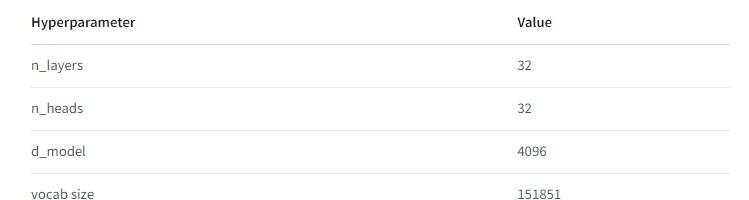
二、模型基本信息
- QWen-7B是基于Transformer的预训练语言模型,采用了与LLaMA类似的架构。它使用了公开的超过2.2万亿个tokens的数据和2048个上下文长度进行预训练。这些训练数据覆盖了一般和专业领域,在语言方面重点关注英语和中文。
- QWen-7B-Chat通过对齐机制微调以符合人类意图,包括面向任务的数据,以及特定的以安全和服务为目标的数据。
- 阿里云在技术文档中还公布了模型训练细节。模型训练使用了AdamW优化器,序列长度为2048,batch size为2048,这意味着每次优化都会累积超过400万个tokens。训练还采用了余弦学习率scheduler,峰值为3×10^-4,最小值为峰值的10%。模型的权重衰减和梯度裁剪参数分别为0.1和1.0。
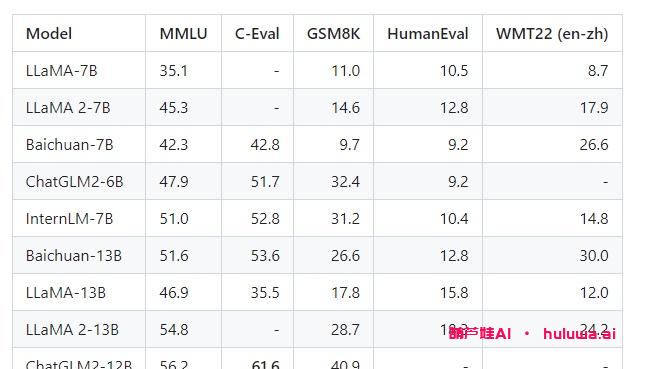
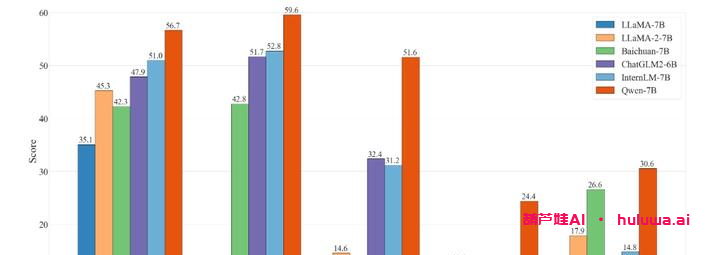
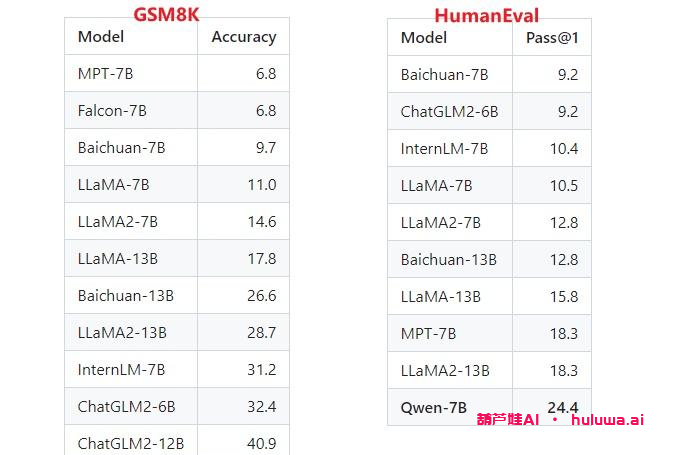
三、模型表现和开销
QWen-7B在MMLU、C-Eval、GSM8K、HumanEval、WMT22等数据集上的表现都是最好的。与其他参数级别相似的开源模型相比,QWen-7B的表现效果更好,甚至超过了一些更大规模的语言模型。同时,大家对数学能力和代码能力也进行了评估,分别在GSM8K和HumanEval数据集上取得了良好的效果。
在模型的开销和部署方面,QWen-7B模型默认精度为bfloat16,显存开销为16.2G。此外,官方还提供了更低精度的量化模型,如Int8和NF4。通过量化,可以将模型的显存开销降低到10.1G和7.4G。当然,量化会导致模型效果的损失。在具体部署方面,阿里云提供了基于Transformers和ModelScope的两种方案,用户可以根据自己的需求选择合适的部署方式。
总结
阿里云开源了70亿参数的大模型QWen-7B和QWen-7b-Chat,对国内大模型行业将产生巨大影响。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...

最专业、最全面的人工智能学习平台,提供最新的AI技术、AI设计、AI导航、AI做图、虚拟人等内容,让您全面了解人工智能技术领域的最新动态,AI学习入门必修都在这里!
{kind=link}
{kind=link}
