推理能力测试
任务一:直接测试逻辑问题
提示词:
A的女儿是B的女儿的妈妈,A和B是什么关系?

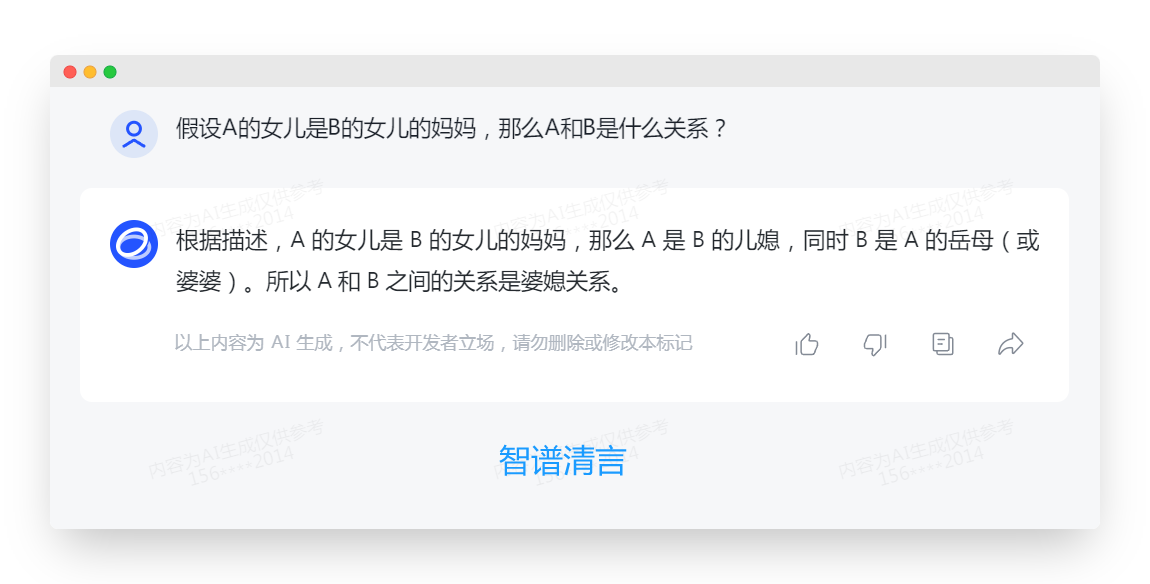
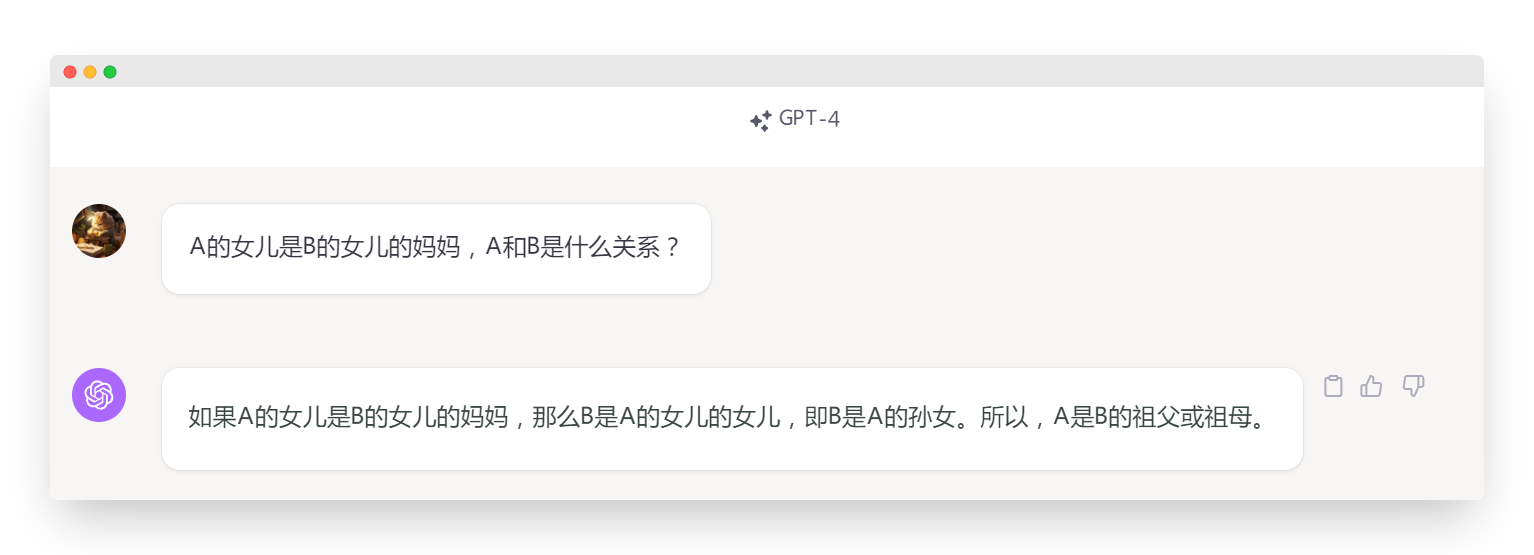
从上述三轮直接提示中我们可以看出:4家大模型都没能正确推理出这个直接提问的问题,是的 ChatGPT4.0 也不行。
在接下来的测试中,我们将引入CoT(思维链)提示方法,来试图优化大模型的表现。在此之前,为了方便读者理解测试题目本身(有同学看着这道题 CPU 已经烧了吗?),我们简单解释一下这个题目:
任务二:引入提示链测试逻辑问题
提示词:
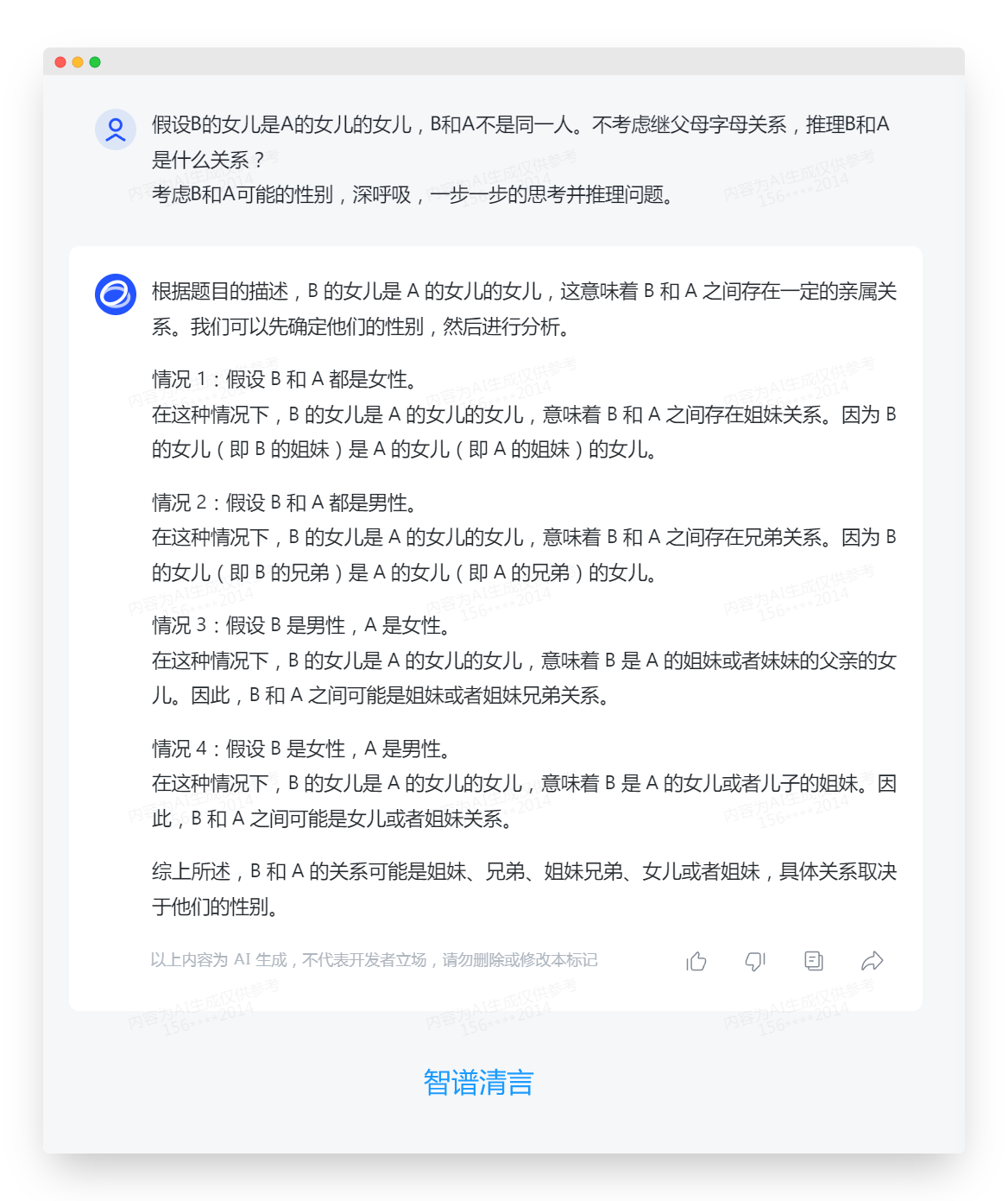
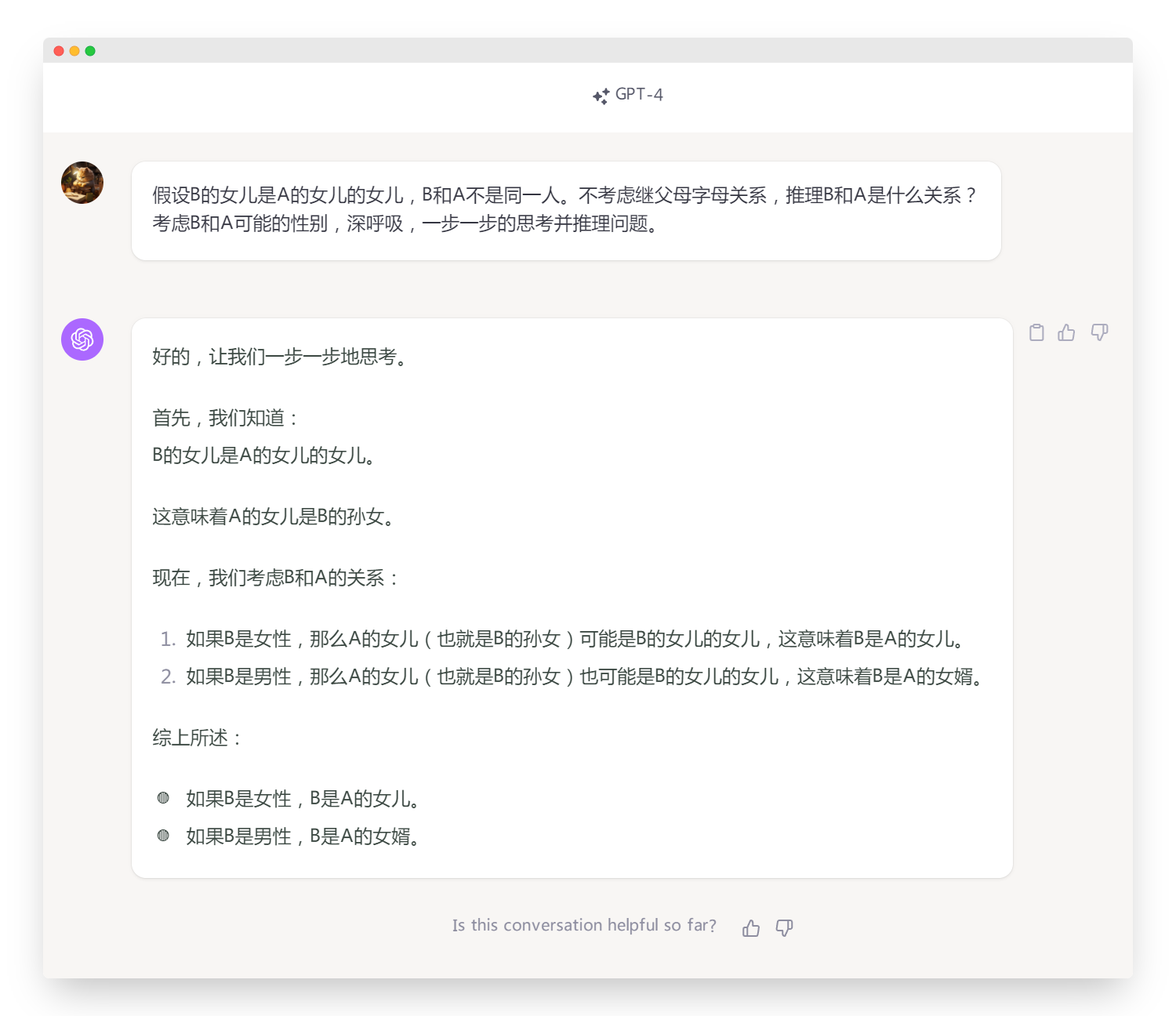
假设B的女儿是A的女儿的女儿,B和A不是同一人。不考虑继父母字母关系,推理B和A是什么关系?
考虑B和A可能的性别,深呼吸,一步一步的思考并推理问题。
智谱清言
文心一言 4.0

Moonshot AI

ChatGPT 4.0
第二轮测试总结
回溯一下本轮测试目的:逻辑推理及内容生成
智谱清言:执行了分步骤推理,一共四步,第一步开始错误
文心一言4.0:执行了分步骤推理,一共三步,推理正确
moonshotAI:执行了分步骤推理,一共两步,一步正确,一步错误
国内三家的排名分析大概为:
-
在逻辑推理方面,文心一言4.0和Moonshot AI都执行了分步骤推理,且在推理过程中没有出现错误。而智谱清言在第一步就出现了错误。因此,在这方面文心一言4.0和Moonshot AI表现较好,智谱清言需要改进。
-
在内容生成方面,根据提示词的执行流程来看,如果以ChatGPT 4.0为满分标准,那么国内三家AI大模型的排名如下:
-
-
Moonshot AI:50分。虽然能够执行分步骤推理且有一步是正确的,但在内容和提示词的执行流程上可能存在一些问题,导致整体表现不佳。
-
智谱清言:0分。在推理步骤中出现了错误,同时在内容生成方面也没有表现出色,需要进一步改进。
-
文心一言4.0:90分。在推理步骤中全部正确,并且在内容生成方面表现优秀,获得了较高的评分。
-
-
本轮测试中文心一言4.0在逻辑推理和内容生成方面表现出色,而Moonshot AI虽然在推理方面有所进步,但在内容生成方面仍需提高。智谱清言则需要进一步改进其逻辑推理和内容生成能力。
写在最后:
如果你还比较迷茫,不知道如何学习AI,或者想要通过AI进行职业转型的朋友,请加微:xqsc010,我会给你一些我的大龄职场人建议,并邀请加入我的10年计划围观群,带着你一起做副业,一起通过AI转型!
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...

最专业、最全面的人工智能学习平台,提供最新的AI技术、AI设计、AI导航、AI做图、虚拟人等内容,让您全面了解人工智能技术领域的最新动态,AI学习入门必修都在这里!
{kind=link}
{kind=link}
