阿里云通义千问Qwen-7B模型:大模型的威力和微调实践

一、Qwen-7B模型的介绍
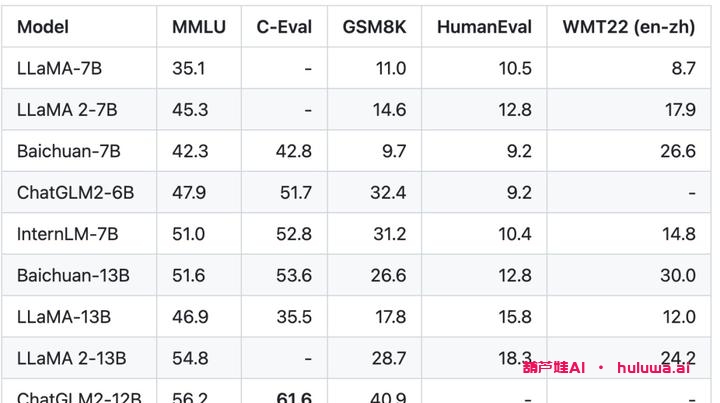
阿里云最新推出的通义千问Qwen-7B模型是一款基于Transformer的大语言模型,规模达到了70亿参数。该模型经过超大规模的预训练数据训练而得,包括网络文本、专业书籍、代码等各种类型的数据。Qwen-7B模型在多个中英文下游评测任务上表现出色。
二、Qwen-7B模型的特点
Qwen-7B模型具有以下特点:
– 大规模高质量训练语料:使用超过2.2万亿tokens的数据进行预训练,覆盖了通用及专业领域的训练语料。
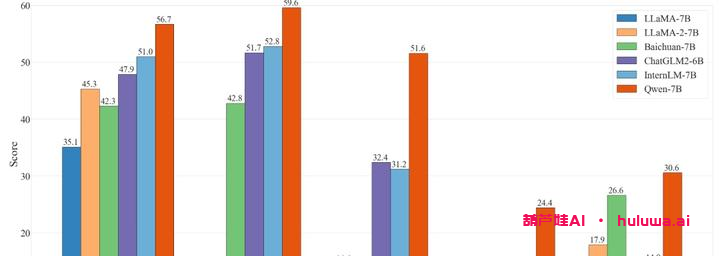
– 强大的性能:在多个中英文下游评测任务中,Qwen-7B模型的效果显著超越了其他相近规模的开源模型。
– 更全面的词表:Qwen-7B使用了约15万大小的词表,对多语言更加友好,方便用户进行能力增强和扩展。
三、微调Qwen-7B模型的实践
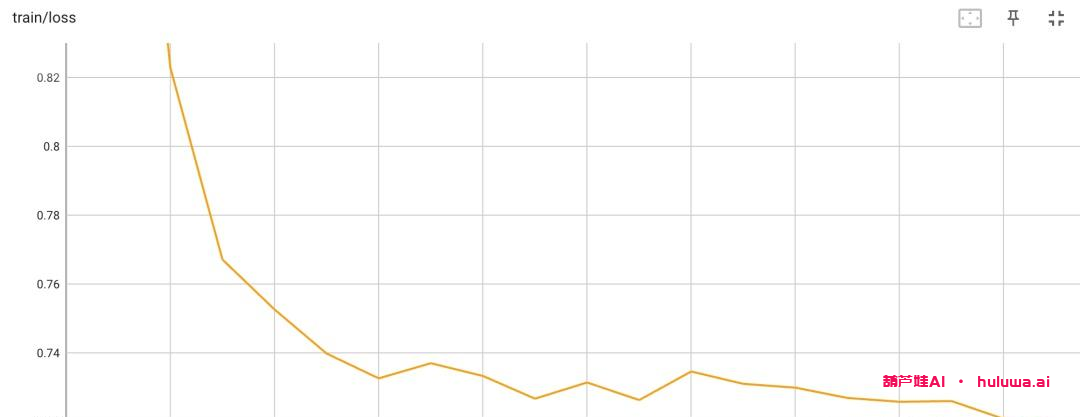
我们使用Firefly项目对Qwen-7B进行了微调,以验证其效果。通过训练和测试,我们发现微调后的Qwen-7B模型在多轮对话和数学推理等任务上表现出色。虽然模型会偶尔出现错误,但它会不断根据用户反馈进行自我纠正并给出正确答案。
总结
阿里云通义千问Qwen-7B模型是一款规模庞大、训练效果优秀的大语言模型。它的发布不仅引起了广泛关注,还为中文开源社区注入了新的活力。通过微调实践,我们验证了Qwen-7B模型的优秀表现。期待未来更多基于Qwen模型的创新应用。
感谢阅读!
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...

最专业、最全面的人工智能学习平台,提供最新的AI技术、AI设计、AI导航、AI做图、虚拟人等内容,让您全面了解人工智能技术领域的最新动态,AI学习入门必修都在这里!
{kind=link}
{kind=link}
