摘要: 中国AI大型模型的崛起与发展历程,以及未来发展趋势和商业应用前景。了解国产大型模型的演进历史、必备技巧和未来风口,AGI课堂推出【程序员的AI大模型进阶之旅】公开课,全免费!
168个国产大模型,都是什么来头?
1785年,瓦特改进了蒸汽机,人类从此摆脱了手工业的桎梏,迈向辉煌的蒸汽时代。1870年,第二次工业革命光芒四溢,人类踏上了电气时代的漫长征程。20世纪70年代后,数字化崛起,人类开始踏入互联网的无尽广阔领域。时至今日,随着AI算法的不断演化和计算需求的迅猛增长,人工智能时代悄然降临。至于那匹引领人类前进的黑马是谁,是Chat GPT,或者是Chat GLM?我不知道。
但可预见的是,AI大型模型的影响力不亚于蒸汽机、电力、数字化对人类生产方式的影响,它们将为社会技术发展带来另一次飞跃,带来新一轮指数级信息爆炸。

而我国,依然在这场革命中涌现出了强大的科技与智慧的力量。
中国本土大型模型的崛起进程始于2017年,当时中国的科研机构与企业积极投身深度学习与自然语言处理领域,默默耕耘,蓬勃至今。据不完全统计,目前国内已有AI大模型168家(数据来源:http://github.com/wgwang/LLMs-In-China)
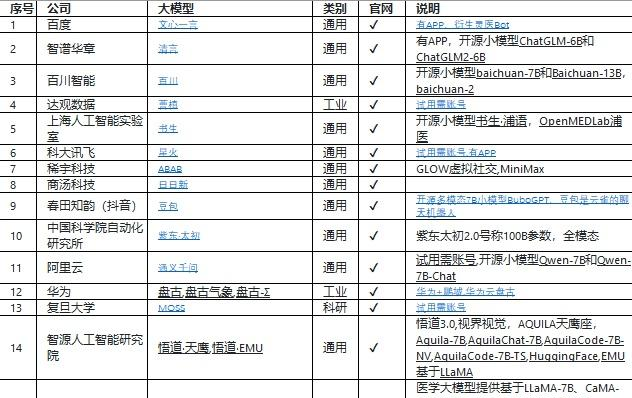
其中,通用模型24个,用于科研/医疗/政务/公共服务的模型40个,其他均为商业应用及服务提供。值得一提的是,其中开源模型只有几家,首当其冲为代表的,分别是智谱AI和清华大学KEG实验室联合发布的ChatGLM,以及百川智能推出的Baichuan 2。
如果想了解更多国产大模型的演进历史、必备技巧,听圈内顶尖技术从业者透露未来大模型风口的话,你绝对不会放过知乎知学堂旗下AGI课堂推出的【程序员的AI大模型进阶之旅】公开课,2天,全部免费!
开源大模型一定比闭源的有前途吗?
如何评价一个AI模型「好不好」「有没有发展」,首先就躲不掉「开源」和「闭源」两条发展路径。
在中国,大型模型可分为两大类,一类以模型本身为核心,另一类则以服务应用为主导。首先是以Chat GLM和百川为代表的通用开源模型。它们的独特之处在于在中文语境下的出色表现。为了提升这类模型在处理中文方面的能力,开发者通常采用两种策略:一是扩大词汇表的规模,二是增加中文语料库的比例。开源模型的优势在于易于使用,只需强大的GPU即可运行。不足之处在于主观体验和论文中的数据可能存在差异,实际使用时性能可能不如宣传所示。
另一类大型模型数量较多,这些大模型通常以套壳Llama或其他类似模型为基础,在特定数据集上进行深度的个性化定制和优化。特点在于它们专注于特定市场细分领域,通过深度定制和优化以提升性能。当然,从论文角度看,某些模型通过特殊方法能够接近或甚至超越Chat GPT,在特定领域的任务上表现出色。
在8月推出的Llama 2中可以看到,模型系列包含70亿、130亿和700亿三种参数变体。此外还训练了340亿参数变体,相比于Llama 1的训练数据多了40%,因此,基于Llama2的开源模型进行数据收集调用及调试的「再生长大模型」,也并非没有可能实现弯道超车。

在我国,目前还是以第二类大型模型主要以服务为主导,如大家比较关注的百度、讯飞等推出了通用大型模型。这些模型不开源,用户需通过其提供的服务来使用。它们不仅提供聊天服务,还需要在特定场景中应用以实现盈利。这些模型的服务模式和费用基本与Chat GPT及其他竞争对手保持一致,以在市场竞争中取得优势。
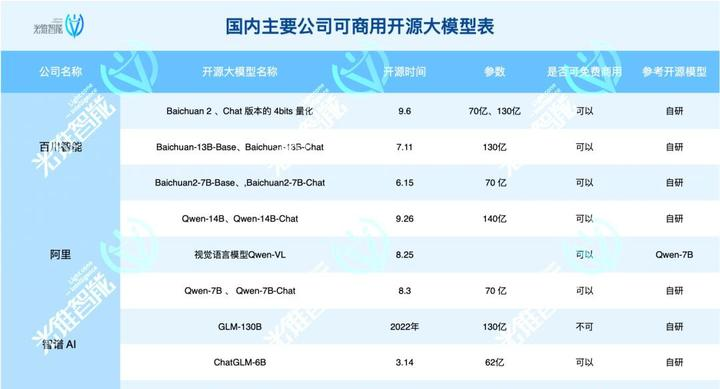
当然,开源是有一定的技术及成本优势的。首先,庞大参数数量的开源大型模型,性能已媲美超级规模封闭模型。其次,通过极少的预算、适度的数据和低阶适应技术(LoRA)等工具,就可以使参数相对较小的开源大型模型达到令人满意的性能水平。这种技术创新降低了训练成本,为企业提供了可替代昂贵闭源模型的低成本解决方案。
自Llama2后,大模型圈风雨欲来,可商用开源成为了下一个各大厂商牟足了劲头实现的目标。可是否开源,难道就是最终评判某个大模型是否可以在这个斗兽场里存活的标准吗?
参数量大的模型一定就比小模型有前途吗?
这两天刚有一篇微软论文指出,CHAT GPT的参数量只有20B(200亿),而不是以往认为的100B以上(很多人认为是175B)。
相比单一的参数量维度,宏观来说,大模型的评价其实可以分为以下几个维度:技术维度、商业应用、伦理责任
从技术角度来讲,哪个模型在深度学习、自然语言处理、计算机视觉等方面有独特的技术优势是最底层的核心逻辑。在此之上,模型的性能通常受训练数据和计算资源的限制。哪个模型拥有更多、更多样化的数据,以及更先进的计算能力?这将直接影响模型的前途。
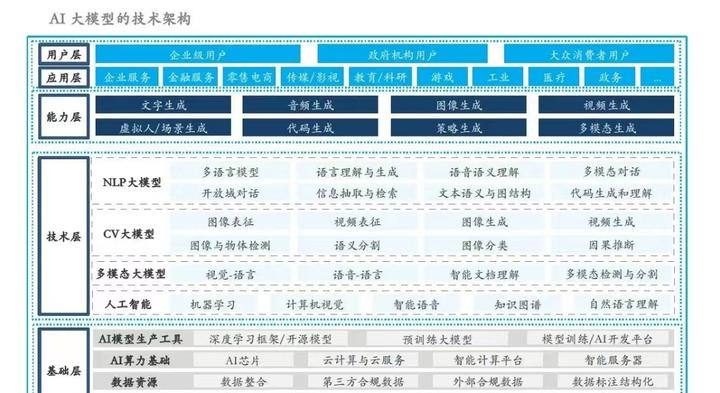
从应用角度来说,大模型厂商自身是否制定了更具前瞻性的商业策略、合理的商业模式,是其长期存活市场的基础。而其选择的赛道是否满足了标的市场的实际需求,在细分垂直领域的适用性能做到最好,市场是否买单,就是保证它前途光明的必要条件。
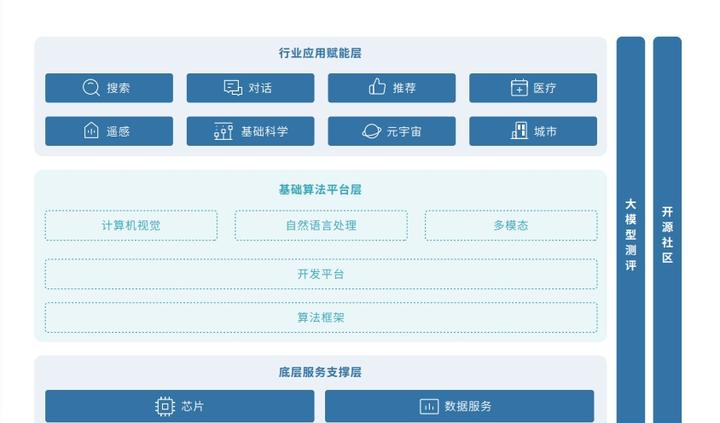
最后一个,也是全世界都在面临的同一个问题,就是机器伦理与合规。哪个模型在道德和伦理方面表现出更高的责任感?是否有明确的道德准则,以确保模型在使用中不会伤害社会和个体?哪个模型有更好的合规准则?更好的数据隐私保护和安全措施?一不小心,《终结者》或许就会变成未来的现实……
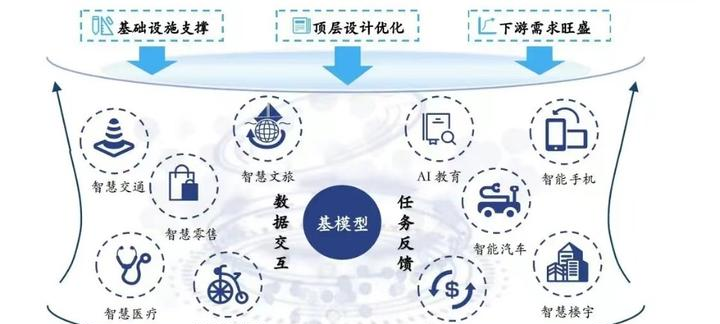
而对于非投资市场及终端用户的业内人士来说,评价一个大模型的是非功过则更以数据和实践见真章。
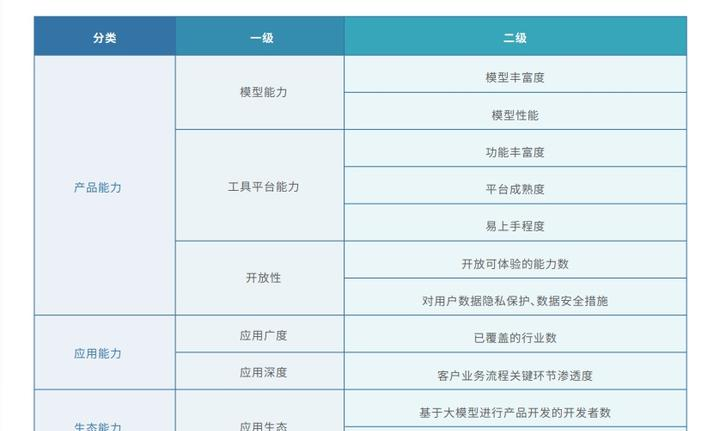
榜单排名高的大模型一定更有前途吗?
其实,内网也早已流传着一份针对于中文通用大模型的综合性测评基准(SuperCLUE),月度更新。根据SuperCLUE最新一期(2023.07)中文通用大模型榜单排名显示,目前排在前三位的分别是来自百度的文心一言(v2.2.0),来自智谱的ChatGLM-130B,以及来自科大讯飞的讯飞星火(v1.5)
当然,榜单仅供参考。毕竟某厂「喜欢给自己飞小红花」的名声过于昭著。对于用户来说,开源/闭源,语料库的偏向性,应用赛道的数据需求等等问题太多了。面对着一个还没有蓄满水的鱼塘,从哪片浅滩挖蛤蜊,就是非常见仁见智的事情。
某AI大厂的架构师就曾经私下说,他们在开发自己的应用模型时,把C-Eval排行靠前的几家都试了一下,效果不好说,某个炒的比较热的模型甚至很意外的崩了。虽然他总是嚷嚷着公司抠没钱自己开源,但好处是也让他挖掘到了一些物美价廉的小LLM,发现实际体验感反而不错。
因此,排名不能完全代表「有前途」,投得热也代表不了「有前途」,甚至广泛意义上对话的人数量够多….好吧,在某种程度上来说可以代表它或许比较有前途。但在2026年高质量语库即将耗尽的预告下,人工喂养也将不再成为强壮大模型的重要决定因素。就当下来说,哪个模型使用感更好,就押宝在哪个模型,无脑傻白甜,最香。
AI大模型涌现元年,资本巨头联合科技大佬们开始一场「诸神之战」,不断扩展数据池,升级硬核算力。高昂的成本,意味着绝对高门槛。不只如此,AI2.0的创业者们要玩得起,技术要求也跃升了一个档次。据悉,能够把基础模型打造成工程化产品的公司,在一两百个大模型中,用两只手就数的过来。也正是因为如此,招兵买马是头等大事,毕竟国内主导深度学习框架和AI框架的高手寥寥可数。
而我们流浪在这一波跨时代,跨世代,甚至跨越人类文明历史的科技变革浪潮中,能做的,只有随之进化,成为超级个体。赶快进入知乎知学堂旗下AGI课堂推出的【程序员的AI大模型进阶之旅】公开课,2天满满干货,限时全部免费!
随着我们一步一步对人工智能的开发和了解,从科幻作品中的描摹,到第一次尝试对话的新奇接触,到深入大模型的底层架构,掌握它,训练它,将大模型作为自己在物理态存在之外的,前人永远无法想象的智慧之触,只用了短短几十年。这些触角最后汇聚在数据的终点,终将可以拨开我们科技未来的层层迷雾。正如现在,虽然对于中国的人工智能来说仍然是路漫漫其修远兮,但我们正慢慢走出这混沌而曲折的序章,奔向光明的前途之路。

相关文章

{kind=link}
{kind=link}
