摘要: 在ChatGpt3.5和文心一言之间,谁更好用? 需要明确ChatGpt是指3.5还是4,目前文心一言的水平并不比ChatGpt3.5逊色,甚至在中文能力上理解还更加优秀。但是哪个更好用,更加取决于谁来定义,定义的标准是什么?了解更多,请关注德里克文的文章。
题目:AI少女、AI孙燕姿、AI换脸、文心一格、文心一言
需要明确ChatGpt是指3.5还是4,目前文心一言的水平并不比ChatGpt3.5逊色,甚至在中文能力上理解还更加优秀。但是哪个更好用,更加取决于谁来定义,定义的标准是什么?

百度文心一言和CHAT GPT都是基于深度学习技术的自然语言处理模型。它们都有各自的优势和使用场景,因此无法简单地比较它们的功能强弱。
每个模型都有其独特的优点和限制,最终选择哪个模型需要根据具体需求来决定。让我来用实际案例测试下关于中文诗歌的理解能力吧。
一. 案例测试
来看看区别吧,就和菜肴一样,萝卜青菜各有所爱,大家可以自行评价下哪个答案更加适合自己。

我采用同样的提示词:
请你扮演一名资深的诗歌作者,创作一篇关于“关于家人团圆的中秋节诗歌”
1. CHAT GPT4.0
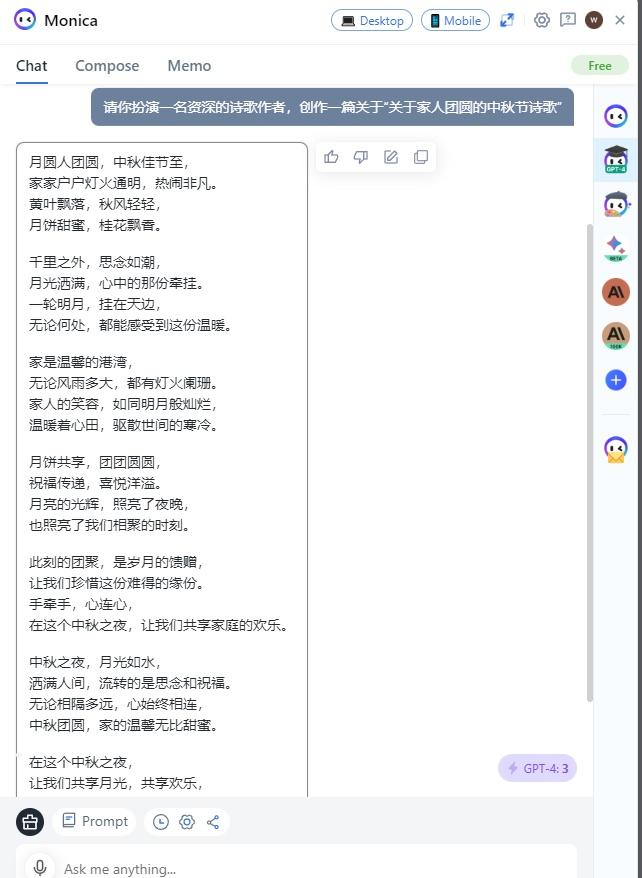
2. CHAT GPT3.5
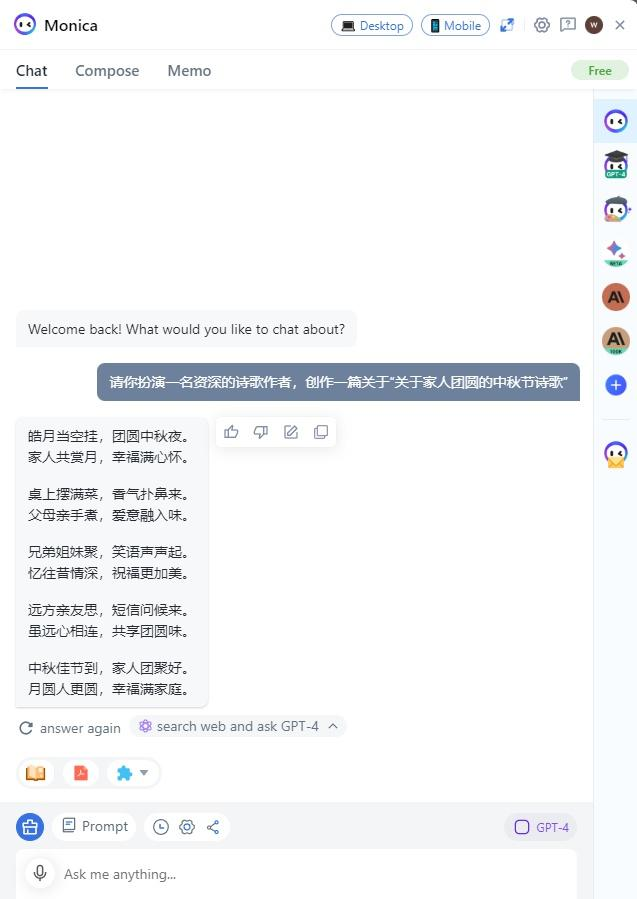
3. 文心一言

二. 评价依据是什么?
当前,大型语言模型无疑是科技互联网领域的热点之一。2022年年底,OpenAI发布了CHAT GPT3.5,迅速在国内人工智能领域引起了广泛的讨论和关注。
根据中国科学技术信息研究所2023年5月发布的不完全统计数据,国内已经有79个参数规模超过10亿的大型语言模型产品,可以说是一场“百模大战”。百度、腾讯、阿里、科大讯飞、商汤、百川智能等知名科技企业,以及一些创业明星,都纷纷参与其中。

与“百模大战”同样令人眼花缭乱的是,有关大型语言模型产品发布的评测榜单层出不穷。按理论来说,能力相近的大型模型在不同榜单上的结果差距应该不大。然而,实际情况是,它们在不同榜单上的排名结果可能存在天壤之别。
三. 国内榜单排名
8月15日,新华社研究院发布了《人工智能大模型体验报告2.0》,该报告对国内主流大模型进行了横向测评。评测结果显示,讯飞星火排名第一,百度文心一言排名第二,阿里通义千问排名倒数第二。

另一方面,SuperCLUE于8月28日发布了中文大模型的排行榜。在该榜单中,GPT-4排名第一,百川智能的Baichuan-13B-Chat名列中文榜单榜首。
此外,在学术界评测榜单C-Eval的最新一期中,云天励飞的大模型“云天书”排名第一,而GPT-4仅位列第十。
这三个榜单分别来自权威媒体、业界和学术界,都是各自领域流行的榜单。然而,它们的排名结果存在巨大差异,更不用说其他榜单了。

报道指出,现在国内外有多达50个知名大模型评测榜单,而它们的排名结果很少一致。
有趣的是,一些榜单甚至使用了相同的评测数据集,但排名结果却存在很大差异。就好像是同一批运动员在不同的场地上比赛,成绩排名却截然不同。那么问题到底出在运动员身上,还是发令枪有问题呢?
四. 大模型的维度评价
从CHAT GPT发布到百模大战爆发,过去的8个月中,评价大型语言模型的标准主要有两个:参数量和评测集。

参数量是指模型中可学习的参数数量,包括权重和偏置。参数量的大小决定了模型的复杂程度,大模型通常具有更多的参数和层数。在2022年,美国发布了一批大型模型,包括Stability AI的Diffusion和OpenAI的CHAT GPT,这些模型的参数数量开始进入了百亿和千亿级别。
从表面上看,具有千亿参数的模型通常表现比百亿级别的模型更好。但也有一些例外情况,并且在相同参数级别下,如何区分模型的优劣呢?

这就引入了大型模型的第二个评测维度:评测集。
评测集是为了有效评估基础模型和微调算法在不同场景和任务上的综合效果而构建的统一基准数据集,可分为公开和封闭两种形态。
这些评测集就像针对不同领域的考卷,通过测试大模型在这些“考卷”上的得分,可以更直观地比较大模型的性能。
在过去,大多数模型机构使用学术类评测集的效果来评判模型的好坏。现在,大模型厂商也开始积极参与学术界的基准测试框架,将其视为权威认可和营销依据。

例如,在Meta发布开源大模型LIama2时,明确介绍了在多个学术评测集上的表现,并公开了与闭源GPT-3.5在GSM8K和MMLU两个评测集上的对比结果。
目前,MMLU是国际上使用最多的大型模型评测集。它源自伯克利大学,考虑了57个学科,涵盖了人文、社科和理工等多个领域的综合知识能力。它已被直接应用于GPT-3.5、GPT-4和PaLM等大型语言模型的研发过程。国内科技巨头在评测时也多数采用这个框架。

商汤在最新财报中特别介绍了其新模型InternLM-123B在近30个学术评测集上的表现,并将MMLU评测成绩排在首位,并与Meta的llama2进行了横向比较。
随后,学术界、产业界、媒体、智库、社区以及传统ICT分析机构都敏锐地关注到这一行业热点,并在今年上半年相继发布了各自的大型语言模型评测榜单。
在当前已有的大型语言模型榜单中,UC伯克利领导的LMSYS是英文领域中最具影响力的榜单。而在中文领域,目前存在多个具有接近影响力的榜单,尚无定论哪个榜单最佳。
结语
我觉得语言大模型是否好用这个目前没有统一的榜单标准能够真正客观,同时由于人工智能语言大模型的飞速发展,差距很快会被弥补,因此纠结于哪个好用并不太有意义,成年人不做选择题,我全都要!你们觉得呢?
我是德里克文,一个对AI绘画,人工智能有强烈兴趣,从业多年的室内设计师!如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!

相关文章

{kind=link}
{kind=link}
