摘要: CHAT GPT新增多模态语音和图像输入功能,提供语音交互和图像理解,开启全新可能性。了解如何使用这些功能,提高用户友好性和沉浸感。
CHAT GPT新功能介绍:多模态语音和图像输入
很强,跟GPT4.0一样,会陆续开放给CHAT GPT Plus用户,时间在两周内。
Plus and Enterprise users will get to experience voice and images in the next two weeks. We’re excited to roll out these capabilities to other groups of users, including developers, soon after.
这就是所谓的多模态吧,因为早在几个月前OpenAI就宣称自己的模型可以接收图片并且进行图像理解。
比如说这个他们之前放出的demo,CHAT GPT会觉得这个接口跟手机连接在一起会很搞笑。

但是直到今天,OpenAI才终于放话出来要开放给用户了。
其实这次的更新就两点:增加了多模态的两个维度:语音voice和图像image 输入。
这意味着CHAT GPT不再仅仅是一个文本驱动的工具,它可以看、听、和说话。这对于用户来说将开启全新的可能性,从实时图像分析到语音交流,这对特定用户群体,如视觉障碍者,也是一个福音。
新增功能一:语音交互
这个对于不方便打字或者打字比较不熟练的人,你可以直接跟它语音交流。
因为之前CHAT GPT的手机APP其实也可以做语音输入,但是只能是文字输出,而现在,可以直接语音交流了,这样可能在很多情况下效率会更高,也更有趣,比如你可以让它讲一个睡前故事等。
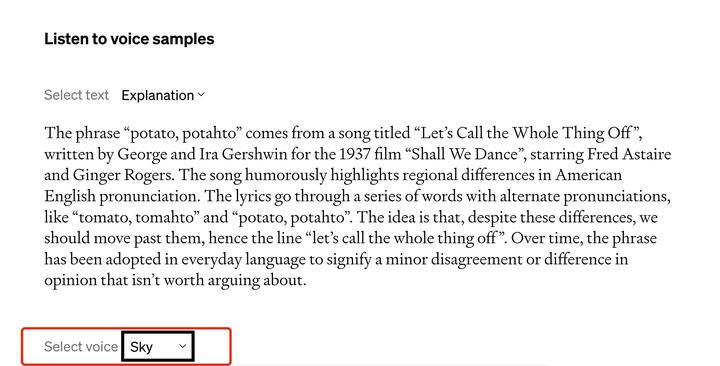
- 开启方法(在开放之后)
- 进入CHAT GPT移动应用的设置。
- 在设置中选择加入语音对话。
- 在主屏幕右上角找到耳机按钮,选择您喜欢的声音,共有五个选择。
- 语音功能使用新的文本到语音技术,可以从文本和示范语音中生成逼真的声音。
- OpenAI与专业声音演员合作,为每个声音创建了独特的特点。
- CHAT GPT还使用开源语音识别系统Whisper来将您的口头输入转录成文本。
新增功能二:图像输入与理解
现在,你可以向CHAT GPT发送多张图像,进行基于图像的对话。这项技术有着广泛的应用,从解决问题到分析工作数据,甚至是计划晚餐,都可以轻松实现。要专注于图像的特定部分,还可以使用移动应用中的绘图工具。这个更新将为我们的数字生活带来更多的便利和创新。
下面是OpenAI的一个案例,你可以看到这种交互是非常有用同时也非常的新颖。
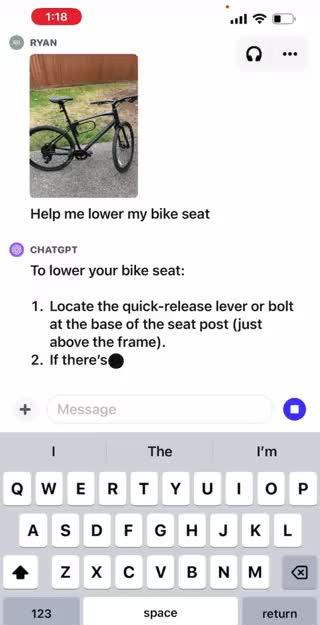
其实看到这里,你就会发现CHAT GPT这类的大模型,做的就是一个人造大脑的工作,基本上就是要把人的五官可以感受到并可以做出分析的能力,赋予给大模型,而最终版的大模型一定是可以听,可以看,可以说,可以感知的一个多模态状态,对于CHAT GPT等大模型的使用,其实对于每个人都很重要,因为它集合了及其庞大的知识和强大的逻辑,可以帮人解决很多实际的问题,对于它的使用,我建议大家可以看看知乎知学堂开设的「大模型与人工智能课程」。
这次的更新有两个很明显的好处:
– 用户友好性:这一更新注重用户友好性。拍照、录制声音,这些都是用户通常已经习惯的操作。这种直观性使得CHAT GPT更容易融入我们的日常生活,比如解决家庭问题、辅助学习或者进行创造性的语音交流。
– 声音合成技术:OpenAI采用了新的文本到语音技术,可以从少量文本和示范语音中生成人类般逼真的声音。这不仅提高了交互的沉浸感,还为有声讲述、音频制作等领域带来了新的创造性可能性。
不过在最后,也有一些顾虑,那就是随着图像的输入,安全和道德问题变得更加重要,如何判断哪些图像有潜在的风险,其实是一个不小的挑战。
以上就是CHAT GPT新增的多模态语音和图像输入功能的介绍,这些功能的加入将使得CHAT GPT更加智能化和易用性,为用户带来全新的体验和应用场景。欢迎大家尝试并体验这些功能的魅力!

相关文章

{kind=link}
{kind=link}
