摘要: CHAT GPT 4.0国内版即将推出,为Plus用户提供声音和图像功能,解锁语音交流和图像输入。立即了解如何使用CHAT GPT多模态功能。
CHAT GPT 4.0国内版即将推出,将会为CHAT GPT Plus用户提供声音和图像功能,预计在接下来的两周内实现。
Plus用户和企业用户将在接下来的两周内体验到语音和图像功能。我们很高兴将这些功能很快扩展到其他用户群体,包括开发者。
这就是所谓的多模态,因为几个月前OpenAI就宣称他们的模型可以接收图片并理解图像。
例如,他们之前发布的演示中,CHAT GPT会觉得将手机与其连接很有趣。

但是直到今天,OpenAI才终于宣布要向用户开放这些功能。
这次更新的两个主要方面是:增加了多模态的两个维度,即语音和图像输入。
这意味着CHAT GPT不再仅仅是一个文本工具,它可以看、听、说话。这将为用户带来全新的可能性,从实时图像分析到语音交流,对于一些特殊用户群体,如视觉障碍者,也是一项重要的进步。
两个主要更新的内容:
1. 语音交互
这对于不方便打字或打字不熟练的人来说非常方便,你可以直接与CHAT GPT进行语音交流。
虽然之前CHAT GPT的手机应用支持语音输入,但只能输出文字,而现在可以直接进行语音交流,这在许多情况下将提高效率,也更有趣,比如可以要求它讲个睡前故事。

还有各种音色可供选择。
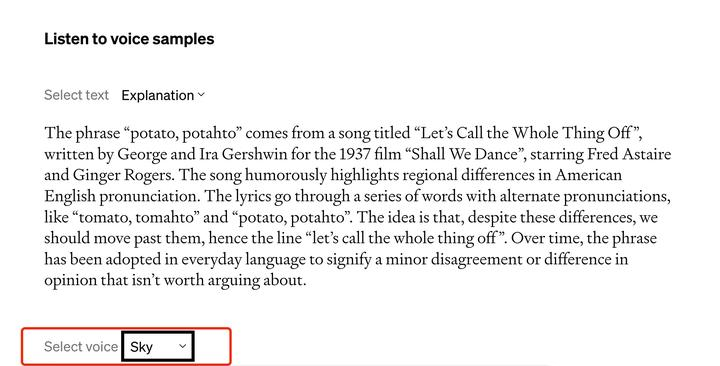
- 如何启用语音交互(在开放后)
- 进入CHAT GPT移动应用的设置。
- 在设置中选择加入语音对话。
- 在主屏幕右上角找到耳机按钮,选择您喜欢的声音,共有五个选择。
- 语音功能使用新的文本到语音技术,可以生成逼真的声音,OpenAI与专业声音演员合作,为每个声音创建了独特的特点。
- CHAT GPT还使用开源语音识别系统Whisper将您的口头输入转录成文本。
2. 图像输入与理解
现在,你可以向CHAT GPT发送多张图像,进行基于图像的对话。这项技术有着广泛的应用,从解决问题到分析工作数据,甚至是计划晚餐,都可以轻松实现。要专注于图像的特定部分,还可以使用移动应用中的绘图工具。这个更新将为我们的数字生活带来更多的便利和创新。
下面是OpenAI的一个案例,你可以看到这种交互是非常有用同时也非常的新颖。
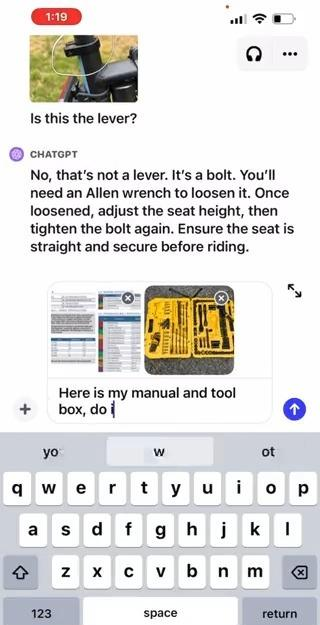
实际上,CHAT GPT这类大模型的任务就是模拟人类大脑的功能,使其能够感知并分析五官的信息。最终的大模型版本将具备多模态能力,包括听、看、说话、感知等。对于CHAT GPT等大型模型的使用对于各种人群都具有重要意义,因为它们集合了丰富的知识和强大的逻辑,可以帮助人们解决各种实际问题。关于如何使用这些模型,可以参考知乎知学堂提供的「大模型与人工智能课程」⬇️ ⬇️ ⬇️
这次更新有两个明显的优点:
用户友好: 这次更新注重用户友好性,拍照、录音是人们已经习惯的操作。这种直观性使得CHAT GPT更容易融入我们的日常生活,例如解决家庭问题、辅助学习或进行创造性的语音交流。

相关文章

{kind=link}
{kind=link}
