OpenAI的商标申请有何商业规划?

一、OpenAI 提交 GPT-5 商标申请
最近,OpenAI 提交了 GPT-5 的商标申请。这引发了人们对于其商业规划的猜测。而在过去的多模态大型模型领域,主要关注的是视觉-文本方向的图文模型。然而,从对话型助手 GPT 出发,语音多模态才是最自然的。目前,传统的语音转文本技术已经能够达到较高的准确度,但在端到端的应用中仍存在一些问题。例如,我们都知道,一句中文对话可能既表示疑问又可能表示不同意,在转成文本后就无法区分。为了应对这一问题,OpenAI 提交的 GPT-5 专利中多次提到了语音技术,体现了他们对于发展多模态语音-文本模型的强烈兴趣。
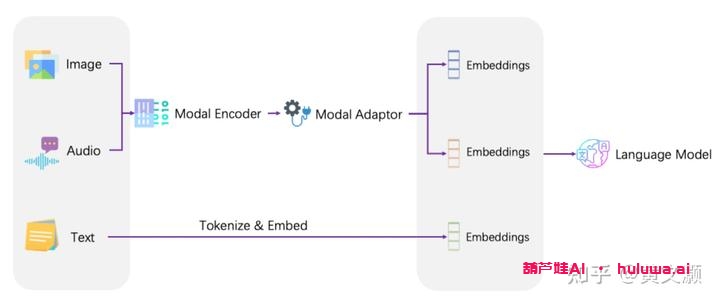
二、Whisper:语音技术的潜力
在探索语音技术的潜力方面,OpenAI 的 Whisper 项目也是一项重要工作。Whisper 不仅是一种优秀的端到端语音转文本工具,还是一个出色的音频编码器,它非常适合用于构建多模态语音-文本模型。通过将语音进行编码,并采用视觉-文本多模态模型的处理方法,我们可以先进行两阶段训练(即特征对准预训练和端到端微调),从而构建出语音-文本模型。这种方法在语音多模态对话中具有很大的潜力。

三、LLaSM:一个多模态开源对话模型
最近,LLaSM(Large Language and Speech Model)这一支持中英双语、语音到文本的多模态开源对话模型引起了广泛关注。该模型的框架结构和之前介绍的 Chinese-LLaVA 模型一致,但我们可以进一步发展一个视觉-语音-文本融合模型。在预训练阶段,我们会冻结模态编码器和大型语言模型的参数,使用跨模态的语音-文本数据对 Adaptor 进行训练,其目标是根据输入的指令生成相应的回复。此外,针对目前缺乏公开的语音多模态指令数据这一问题,我们基于 WizardLM、ShareGPT 和 GPT-4-LLM 等公开数据集构建了语音-文本多模态指令数据集 LLaSM-Audio-Instructions。该数据集将很快开源,有兴趣的读者可以去 huggingface 上试玩。通过自己的试玩体验,可以发现该模型的基本能力还是不错的,能够很好地跟随指令。不过由于语言模型部分使用的是中文指令微调的 LLaMA-7B,缺乏强大的中文知识,所以回答某些问题还不够理想。另外,尽管输入端已经实现了多模态,但如果输出端也能实现多模态将会更有趣。

总结
OpenAI 提交 GPT-5 商标申请,展示了他们在语音多模态领域的商业规划。其中,Whisper 项目作为一种优秀的音频编码器和端到端语音转文本工具,为构建多模态语音-文本模型提供了强大的技术支持。同时,LLaSM 项目作为一个支持中英双语、语音到文本的多模态对话模型,为语音多模态对话的研究与应用带来了新的可能。这些创新和突破为我们的科技世界带来了更多的想象空间。
感谢各位读者的阅读与支持!
(以上为参考文章改写生成的文章,以下为对读者的感谢陈述)

相关文章

{kind=link}
{kind=link}
