近日Microsoft研究人员发布了一种多模态模型CoDi,这是一种可组合的、基于扩散的人工智能模型,可以同时处理和生成多种模式的内容,包括文本、图像、视频和音频。
以实现人工智能多模态效果时,不再需要接入各种能力模型,而是由单模型完成的跨越!
可组合扩散(CoDi):
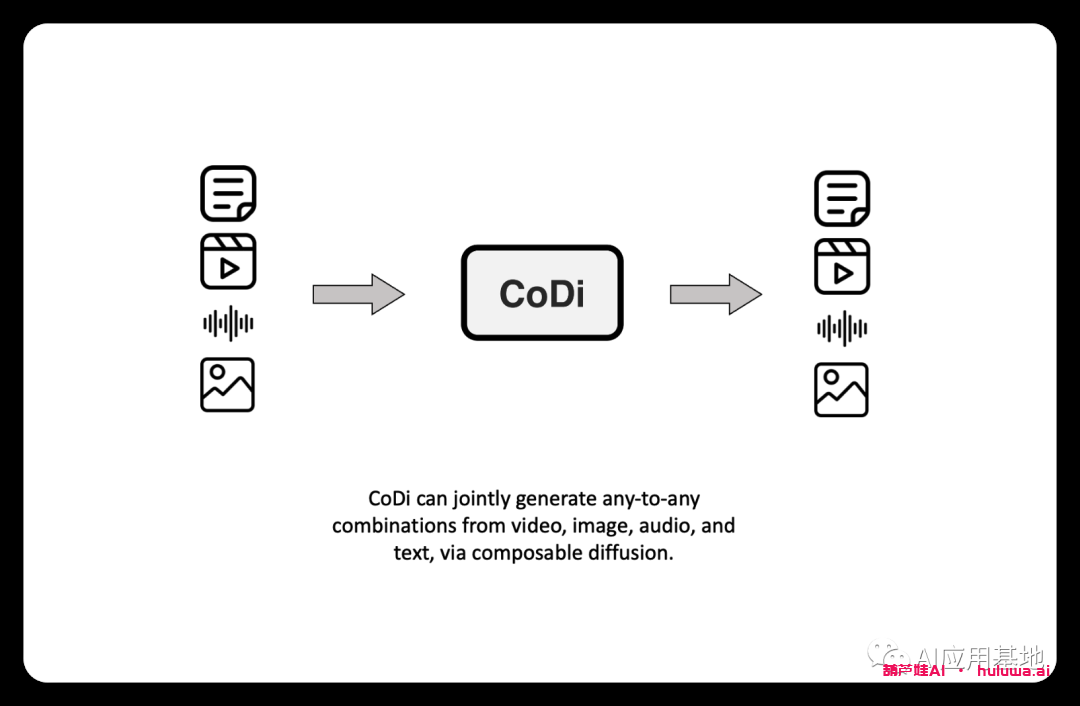
这是一种新颖的生成模型,能够从输入模态的任意组合生成输出模式的任意组合,例如语言,图像,视频或音频。与现有的生成式人工智能系统不同,CoDi可以并行生成多种模态,其输入不限于文本或图像等模态的子集。
尽管缺乏许多模态组合的训练数据集,研究人员使用了一种对齐策略,在输入和输出空间中对齐模态。这允许 CoDi 自由地对任何输入组合进行条件调整并生成任何一组模态,即使它们不存在于训练数据中。
CoDi采用一种新颖的可组合生成策略,该策略涉及通过在扩散过程中桥接对齐来构建共享的多模态空间,从而能够同步生成相互交织的模态,例如时间对齐的视频和音频。CoDi 具有高度可定制性和灵活性,可实现强大的联合模态生成质量,并且优于或与单模态合成的单峰最先进的技术相媲美。
跨模式 AI 开发的挑战
CoDi 解决了传统单模态 AI 模型的局限性,为组合特定于模态的生成模型的繁琐和缓慢的过程提供了一种解决方案。
这种新颖的模型采用了独特的可组合生成策略,该策略在扩散过程中桥接对齐,并促进相互交织模式的同步生成,例如时间对齐的视频和音频。
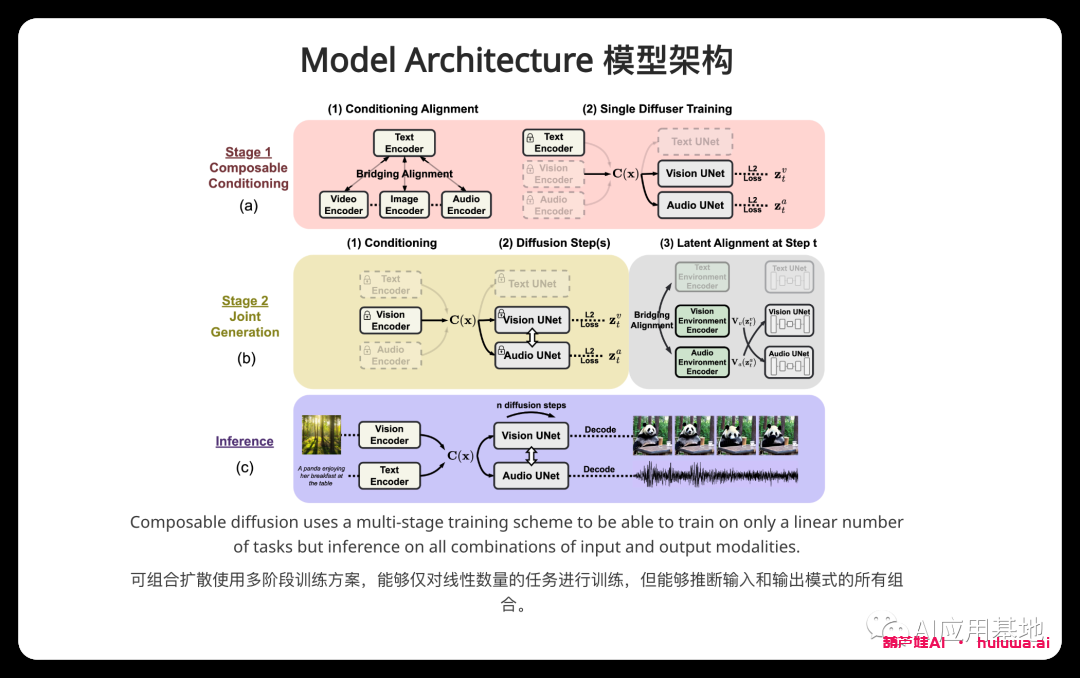
CoDi的训练过程也很独特。它涉及将图像、视频、音频和语言等输入形式投影到公共语义空间中。这允许灵活处理多模态输入,并且通过交叉注意力模块和环境编码器,它能够同时生成输出模态的任意组合。
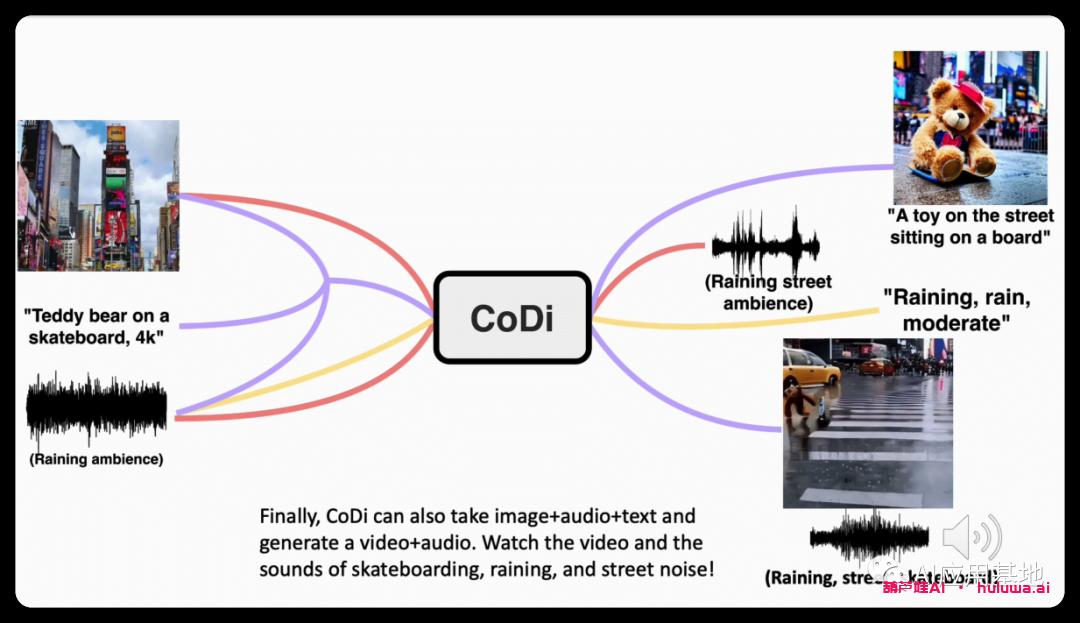
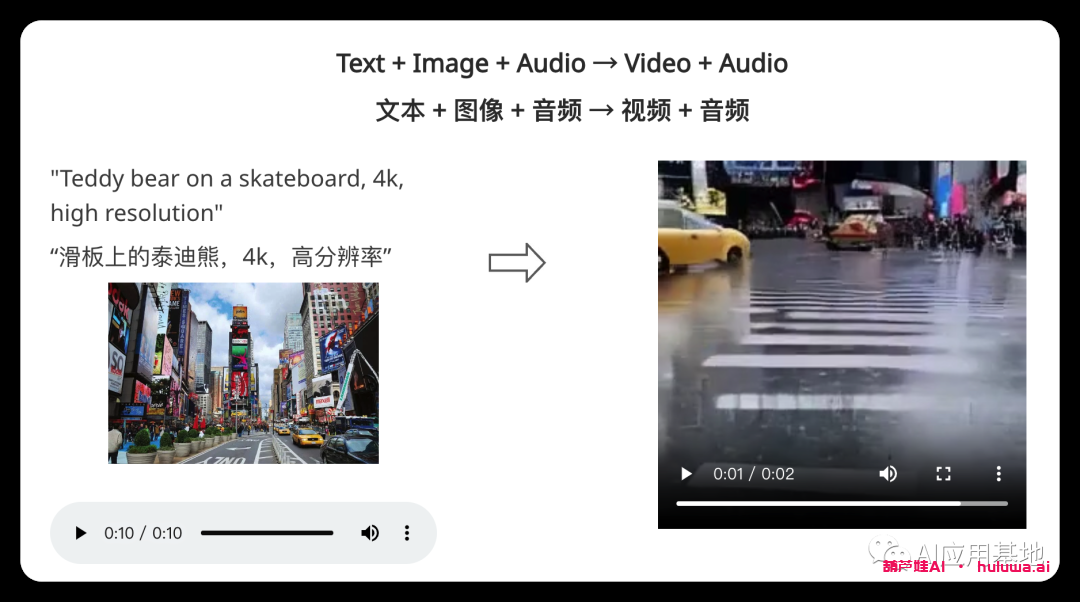
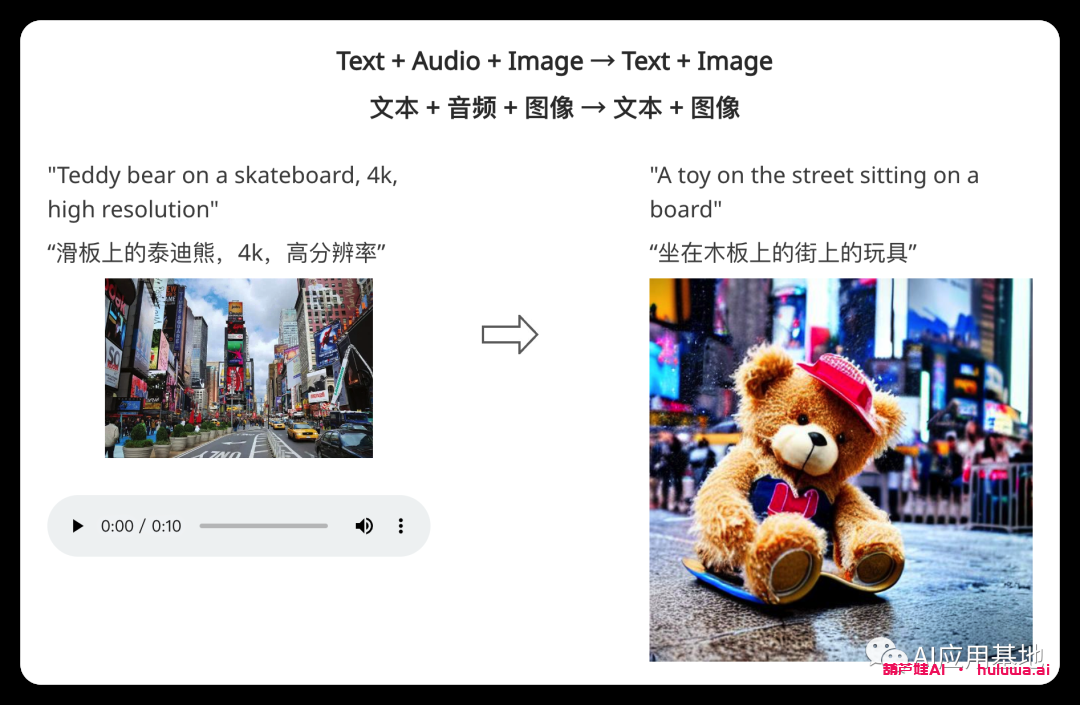
“滑板上的泰迪熊,4K,高分辨率”
研究人员提供了CoDi功能的示例。展示了它从单独的文本,音频和图像提示生成同步视频和音频的能力。在一个示例中,输入包括文本提示“滑板上的泰迪熊,4k,高分辨率”,时代广场的图像和雨声。
CoDi制作了一段简短但质量低下的视频,描绘了泰迪熊在雨中滑板,伴随着雨声和街道噪音的同步声音。
示例
多输出的联合生成?
模型采用单个或多个提示(包括视频、图像、文本或音频),以生成多个对齐的输出,例如带有伴随声音的视频。
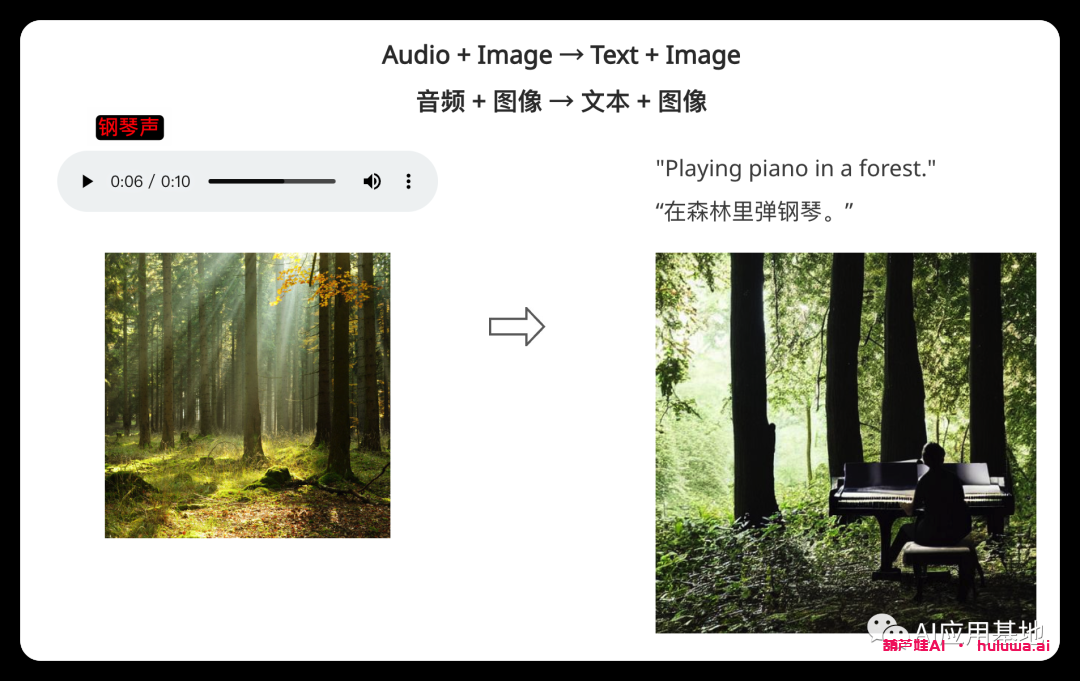

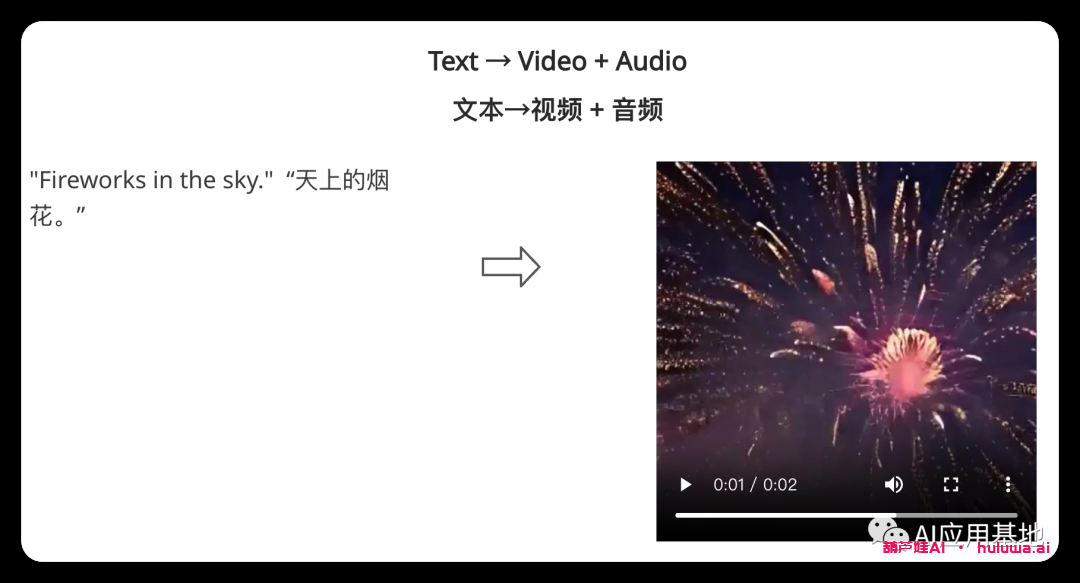
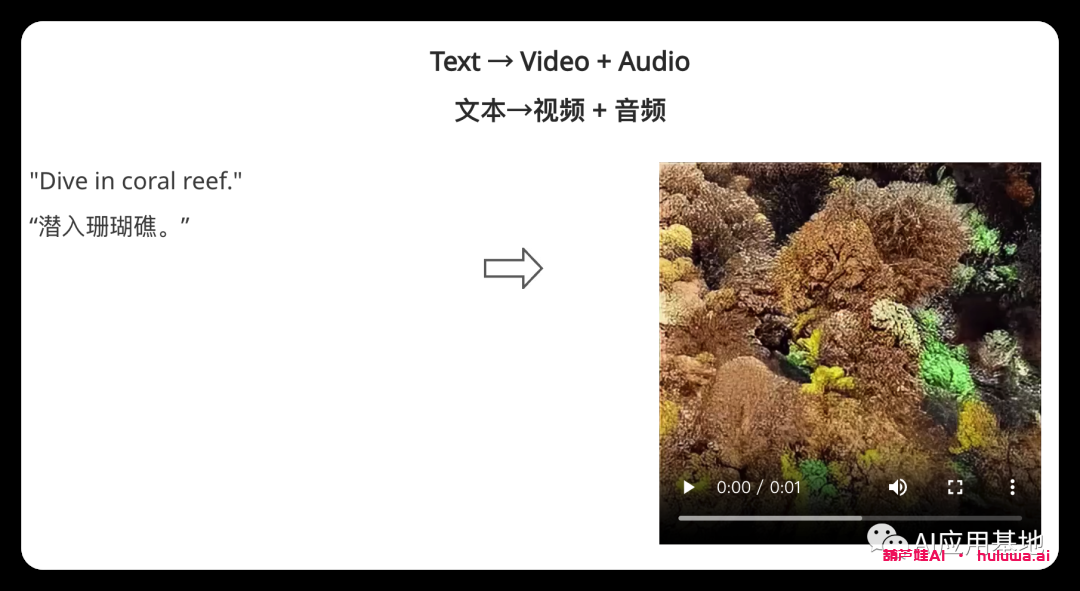
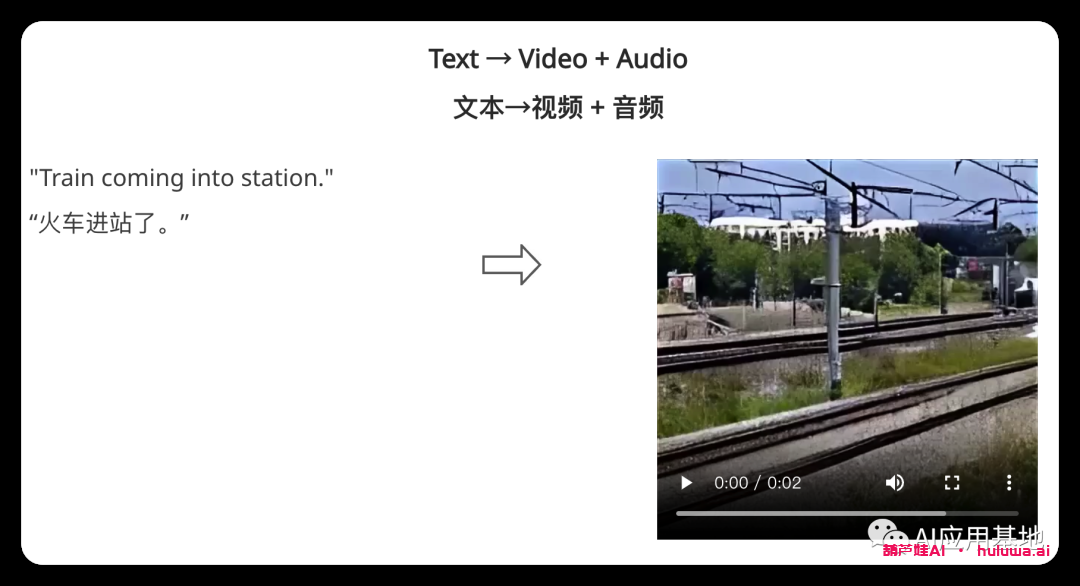


Multiple Conditioning 多重调理?
模型接受多个输入,包括视频、图像、文本或音频以生成输出。
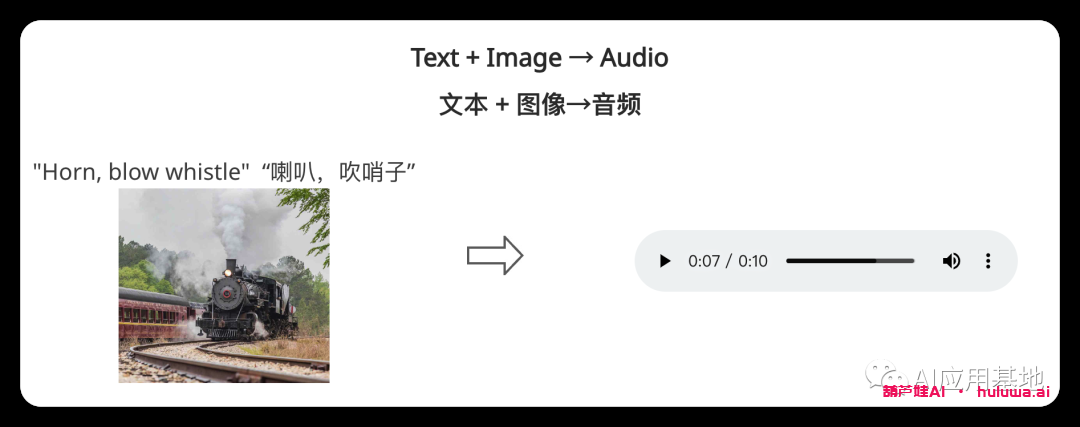
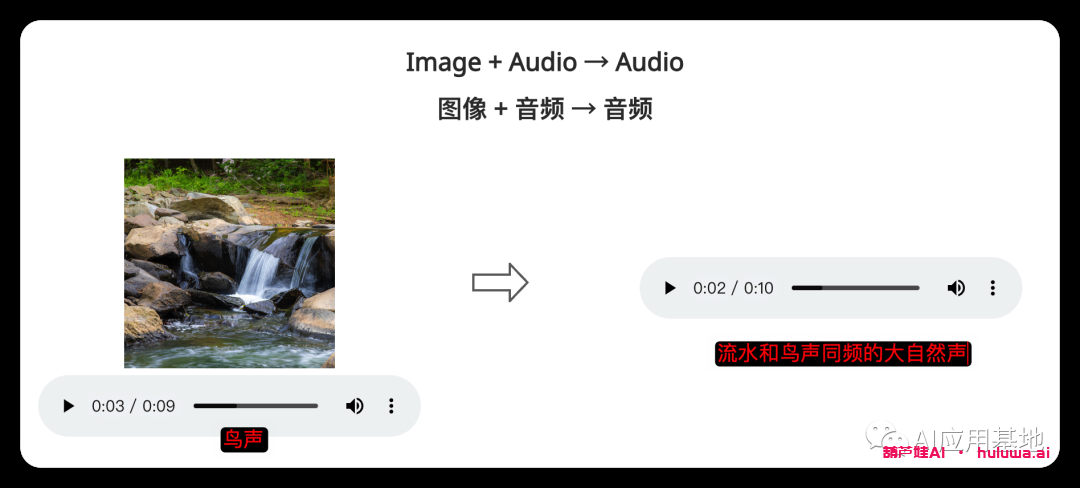
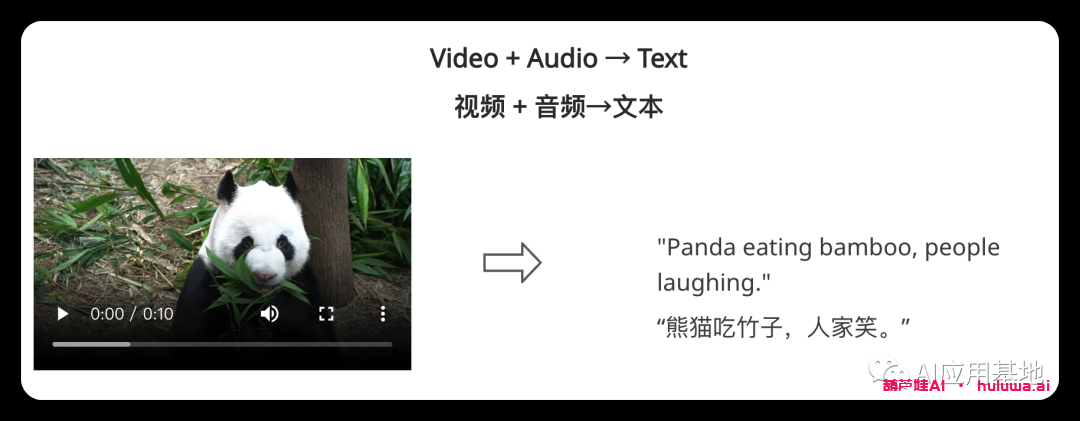


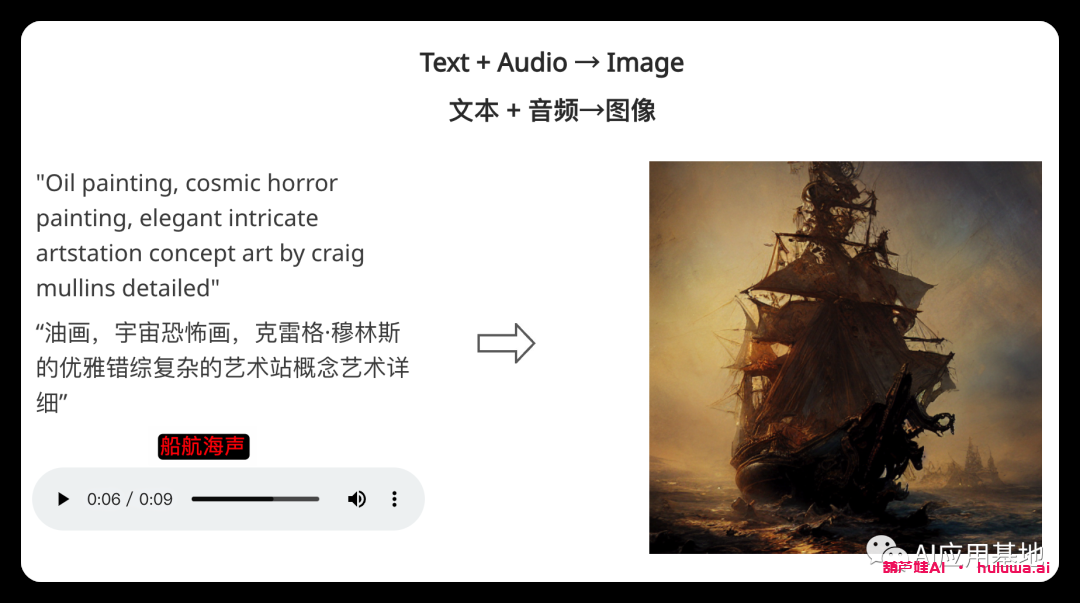

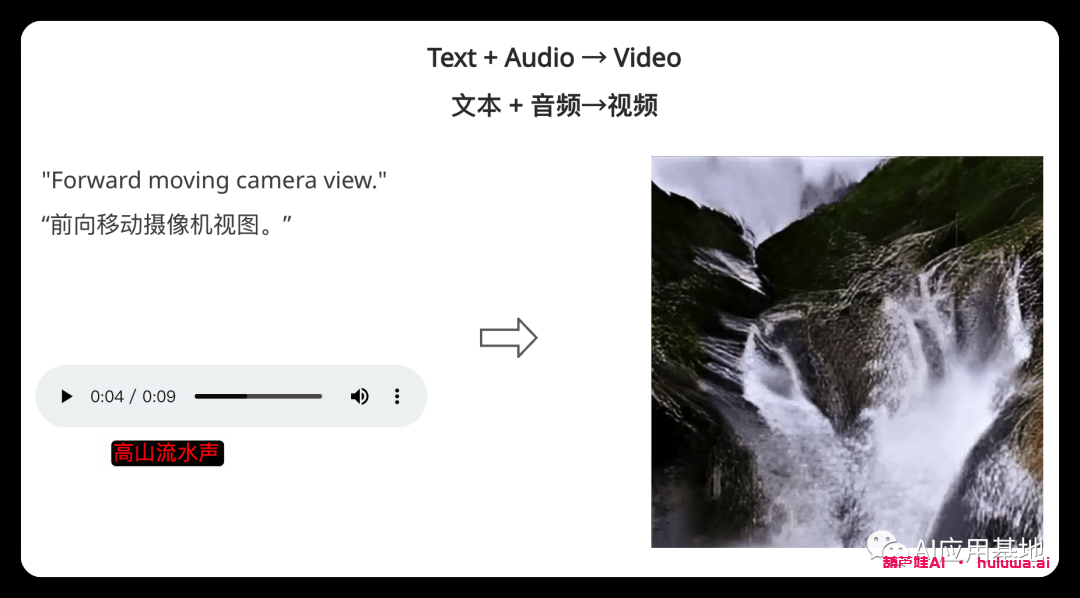
Single-to-Single Generation单到单的生成?
模型采用单个提示(包括视频、图像、文本或音频)来生成单个输出。


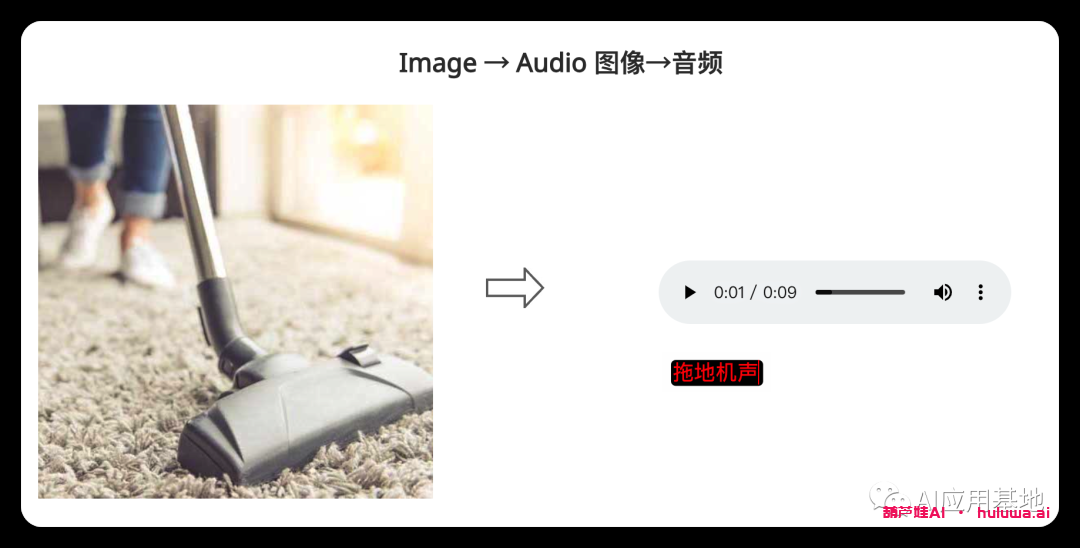

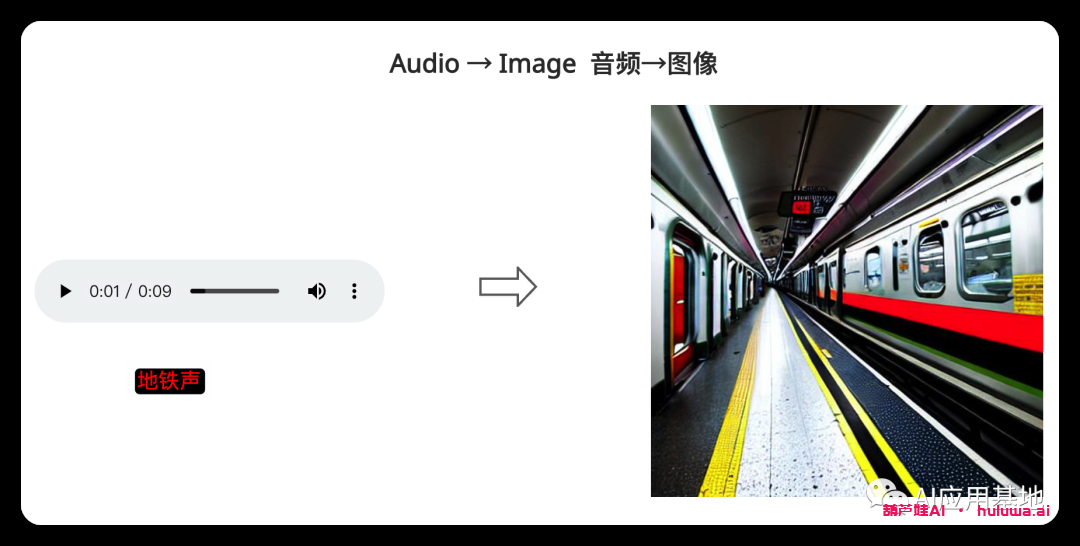


相关文章

{kind=link}
{kind=link}
